循环编码器多模态情感分析
2021-02-22 Jay Saligia 7 mins 暮晚
MULTIMODAL SPEECH EMOTION RECOGNITION USING AUDIO AND TEXT
2018
用两个循环编码器来对多模态情感分析建模
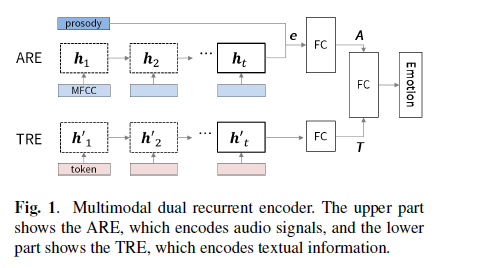
 ARE是Audio Recurrent Encoder,TRE是Text Recurrent Encoder。具体RNN方案为GRU,因为GRU权重参数比LSTM少。
ARE是Audio Recurrent Encoder,TRE是Text Recurrent Encoder。具体RNN方案为GRU,因为GRU权重参数比LSTM少。
ARE
对于输入数据\(\mathbf x_t\)(\(\mathbf x_t\)为第\(t\)个MFCC特征,\(\mathbf X=\{x_{1:t_a}\}\)),隐状态计算方式为\(\mathbf h_t=f_\theta(\mathbf h_{t-1},\mathbf x_t)\),最后一个隐状态输出为\(\mathbf h_{t_a}\),\(\mathbf h_{t_a}\)被认为表示了所有的声音序列的数据。将\(\mathbf h_{t_a}\)与一个韵律特征(prosodic,使用openSMILE得到)拼接:\(\mathbf e={\rm concat} \{\mathbf h_{t_a}, \mathbf p\}\),\(\mathbf x_t\in \mathbb R^{39},\mathbf p \in \mathbb R^{35}\)。训练目标为: \(\hat{y}_i={\rm softmax}(\mathbf e^TM+b)\\ \mathcal L=\log\prod_{i=1}^N\sum_{c=1}^Cy_{i,c}\log(\hat{y}_{i,c})\) TRE
用NLTK来将讲稿文字转换为token,训练目标与ARE一致,\(\hat{y}_i={\rm softmax}(\mathbf h_{last}^TM+b)\)
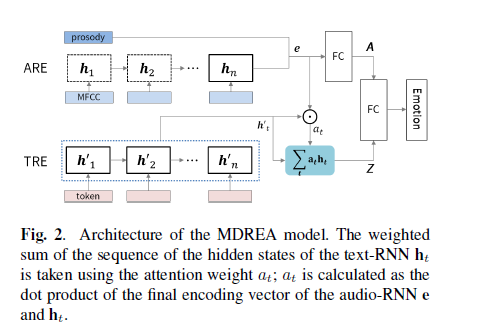
MDRE(Multimodal Dual Recurrent Encoder)
\(\rm e\)经过一层FC,变为\(\rm A\);\(\mathbf h_{last}^T\)经过一层FC,变为\(\rm T\),有: \(\mathbf A=g_\theta(\mathbf e), \mathbf T=g^\prime_\theta(\mathbf h_{last})\\ \hat{y}_i={\rm softmax}({\rm concat(\mathbf A, \mathbf T)} ^TM+b)\) MDREA(Multimodal Dual Recurrent Encoder with Attention)
加了注意力机制。
\(\begin{align*}
& a_t = \frac{\exp(\mathbf e^T\mathbf h_t)}{\sum_t \exp(\mathbf e^T\mathbf h_t)},将audio的特征与每个词语相乘\\
& \mathbf Z=\sum_ta_t\mathbf h_t,\\
& \hat{y}_{i,j}={\rm softmax}({\rm concat(\mathbf Z, \mathbf A)} ^TM+b)
\end{align*}\)
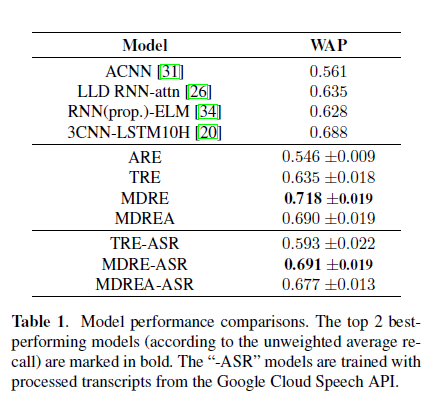

作者提出,MDREA效果比MDRE还差,是因为缺乏足够的数据来对加了注意力机制的网络进行训练。neutral类别更容易迷惑分类准确性,对于happy类和neutral类,文字比音频传递更有效。

