多模态表示与单模态表示共同训练
2021-02-23 Jay Saligia 18 mins 深深晚景满秋声
Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for Multimodal Sentiment Analysis
2021-AAAI
对于表示训练的方法分为了两个:forward guidance和backward guidance
forward guidance
forward guidance致力于设计模态之间的交互模块,但是因为这样追求统一的设置,很难捕获特定模态的信息。
backward-guidance
backward-guidance中,提出了使用额外的损失函数作为先验限制,使得模态表征包含了一致和互补的信息。
本文采取的是backward-guidance,使用了一种自监督的多任务学习策略。主要基于两个直观的感受:1)标签之间的距离与模态表示和类的中心是高度相关的;2)单模态标签和多模态的标签是高度相关的。本文基于多模态标签和模态表示设计了一个单模态标签生成模块。

实施方法
多模态情感分析(MSA)可以是一个回归任务或者是一个分类任务,在本文中把它作为一个回归任务。因此,Self-MM分别使用文本、音频、视频(\(I_t,I_a,I_v\))作为输入,输出一个情感倾向结果\(\hat{y}_m\in R\)。在训练阶段,为例辅助表示训练,Self-MM使用额外的三个模态的输出\(\hat{y}_s\in R,s\in \{ t,a,v \}\),最终仍使用\(\hat{y}_m\)作为结果。
多模态任务
对于多模态任务分为三个部分:特征模块,特征融合模块和输出模态。对于文本模态,使用BERT去表征句子,BERT最后一层的第一个词的向量来表示整个句子: \(F_t = BERT(I_t;\theta_t^{bert})\in R^{d_t}\)
通过预训练工具ToolKIts从原始数据中抽取出音频和视频模态$I_a\in R^{l_a\times d_a}$和$I_v \in R^{l_v\times d_v}$。使用一个单向LSTM来获取时间特征。最后,采用最终状态隐藏向量作为整个序列表示: \(F_a=sLSTM(I_a;\theta_a^{lstm})\in R^{d_a}\\ F_v=sLSTM(I_v;\theta_v^{lstm})\in R^{d_v}\) 然后将所有的单模态表示进行连接并映射到低维度$R^{d_m}$: \(F_m^*=ReLU(W_{l1}^{mT}[F_t;F_a;F_v]+b_{l1}^m)\\ W_{l1}^m \in R^{(d_t+d_a+d_v)\times d_m}\) 使用融合后的表示$F_m^*$预测多模态情感: \(\hat{y}_m=W_{l2}^{mT}F_{m}^{*}+b_{l2}^m\\ W_{l2}^m\in R^{d_m\times1}\)
单模态任务
对于三个单独的模态,它们共享了多模态的结果。为了减少不同模态之间的维度差异,将这三个模态都映射到新的特征空间,然后使用线性回归得到单模态结果: \(F_s^*=ReLU(W_{l1}^{sT}F_s+b_{l1}^s)\\ \hat{y}_s=W_{l2}^{sT}F_s^*+b_{l2}^s\\ s\in \{ t,a,v \}\) 为了引导单模态任务的训练过程,本文使用了一种单模态标签生成模块(Unimodal Label Generation Module,ULGM)来得到单模态标签: \(y_s=ULGM(y_m,F_m^*,F_s^*)\\ s\in \{ t,a,v \}\) 只在训练阶段使用单模态任务训练。
ULGM
为了避免对网络参数更新的不必要干扰,ULGM被设计为非参数模块。总的来说就是ULGM计算了从模态表示到类中心的相对距离。

如图2显示,在多模态任务中,结果是偏向pos的,但某个单模态结果是偏向neg的,因此单模态监督参数$y_s$被添加了一个偏移$\delta_{sm}$到多模态标签$y_m$。
相对距离
因为不同的模态存在于不同的特征空间,使用绝对距离是不够精准的,因此使用一种相对距离。在训练阶段设定pos中心$C_i^p$和neg中心$C_i^n$: \(C_i^p=\frac{\sum_{j=1}^NI(y_i(j)>0)\cdot F_{ij}^g}{\sum_{j=1}^NI(y_i(j)>0)}\\ C_i^n=\frac{\sum_{j=1}^NI(y_i(j)<0)\cdot F_{ij}^g}{\sum_{j=1}^NI(y_i(j)<0)}\\ i\in \{ m,t,a,v \},N\ is\ the \ number \ of \ training \ samples,\ I(\cdot)\ is \ a \ indicator\ function,\\ F_{ij}^g\ is \ the \ global \ representation\ of \ the \ j_{th} \ sample \ in \ modality\ i.\) 对于模态表示,使用L2范式衡量$F_i^*$和类中心: \(D_i^p=\frac{||F_i^*-C_i^p||_2^2}{\sqrt{d_i}}\\ D_i^n=\frac{||F_i^*-C_i^n||_2^2}{\sqrt{d_i}}\\ i\in \{ m,t,a,v \},\ d_i \ is \ the \ representation \ dimension\) 定义模态表示和pos中心、neg中心的相对距离: \(\alpha_i=\frac{D_i^n-D_i^p}{D_i^p+\epsilon}\\ i\in \{ m,t,a,v \}\) 本文认为$\alpha_i$和最终的结果应该是正相关的,有如下关系(单模态于多模态正相关): \(\frac{y_s}{y_m}\propto\frac{\hat{y}_s}{\hat{y}_m}\propto\frac{\alpha_s}{\alpha_m} \rightarrow y_s=\frac{\alpha_s * y_m}{\alpha_m} \\ y_s-y_m\propto\hat{y}_s-\hat{y}_m\propto\alpha_s-\alpha_m\rightarrow y_s=y_m+\alpha_s-\alpha_m (\alpha_m=0)\\ s\in \{ t,a,v \}\) 综合考虑如上式子: \(\begin{align} y_s & =\frac{y_m * \alpha_s}{2\alpha_m}+\frac{y_m+\alpha_s-\alpha_m}{2}\\ &=y_m+\frac{\alpha_s-\alpha_m}{2}*\frac{y_m+\alpha_m}{\alpha_m}\\&=y_m+\delta_{sm}\\& s\in \{ t,a,v \} \end{align}\)
更新规则
由于模态表示的动态改变性,为了减轻负面影响,本文设计了一个基于动量的更新策略,它将新生成的值与历史值结合起来($i$为epoch):
\(y_s^{(i)}= \left \{
\begin{aligned}
& y_m & i=1 \\
& \frac{i-1}{i+1}y_s^{(i-1)}+\frac{2}{i+1}y_s^i & i>1
\end{aligned}\right.\)

Equation(10): \(L=\frac{1}{N}\sum_i^N(|\hat{y}_m^i-y_m^i|+\sum_s^{ \{ t,a,v \} }W_s^i*|\hat{y}_s^i-y_s^{(i)}|)\\W_s^i=tanh(|y_s^{(i)}-y_m|)\)
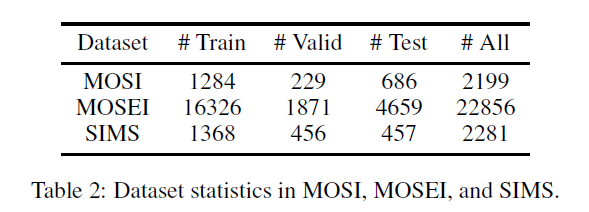
数据集
结论
Ablation Study


生成的音频和视觉标签并没有受到预处理特征的足够重视的限制。
