语音情感识别的对齐
2021-02-22 Jay Saligia 4 mins 丑的别致
Learning Alignment for Multimodal Emotion Recognition from Speech
2020-滴滴公司
首次将speech和text进行对齐
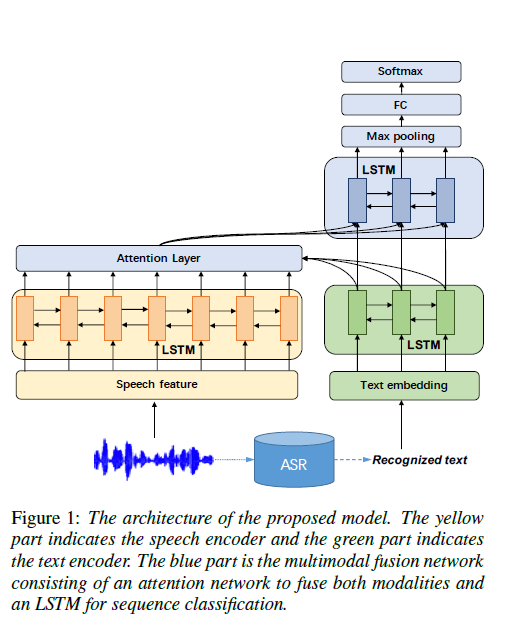
一条路径直接从音频编码中抽取特征,另一条路径使用ASR系统来生成文本并且转换为embedding。
对音频信号\([x_1,\cdots,x_N]\)用双向LSTM编码(frames:window=20ms,shifted=10ms),隐状态输出为\(S_i=[\overrightarrow {s}_i, \overleftarrow {s}_{N-i+1} ]\),用Google Cloud Speech API做ASR,输入文本\([e_1,\cdots,e_N]\),用双向LSTM编码得到隐状态输出为\(h_j=[\overrightarrow{h}_j,\overleftarrow{h}_{M-j+1}]\)。将音频和文本隐状态输入到Attention Layer: \(\begin{align*} & a_{j,i}=\mathbb {tanh}(u^Ts_i+v^Th_j+b),u和v是可训练参数\\ & a_{j,i}=\frac{e^{a_{j,i}}}{\sum_{t=1}^Ne^{a_{j,i}}},softmax\\ & \tilde{s}_j=\sum_ia_{j,i}s_i,对于词语j,将它与所有音频的特征进行attention加权 \end{align*}\) 将经过音频文本融合的\(\tilde {s}_j\)与原文本隐状态连接\([\tilde{s}_j,h_J]\),输入到双向LSTM,得到\(c_j\),经过最大池化和FC之后,用softmax分类。
音频特征用Python库pyAudioAnalysis提取,词嵌入用300维GloVe embedding作为预训练。

-分享这篇博客-
