细粒度多层次图推理
2021-02-22 Jay Saligia 47 mins 可爱狗狗
读《Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning》
Abstract
随着视频资源在网络上的快速增长,视频和文本之间的跨模态检索得到越来越多的重视。目前的主流跨模态相似性度量方法都是去学习一个联合表示空间。但是,简单的嵌入方法不能够表示复杂的视觉和文本细节,比如场景、物体、行为和它们的组成部分。为了改善细粒度的视频-文本检索,本文提出了一种分层图形推理(Hierarchical Graph Reasoning)模型,将视频-文本匹配分解为全局-局部的级别。该模型将文本分解为包含事件(event)、动作(action)、实体(entity)三层的层次语义图,并通过基于注意力的图推理生成层次文本嵌入。不同级别的文本可以为跨模态匹配捕获全局和局部的细节信息以指导学习不同层次的时评表示。在三个视频-文本数据集上的实验结果体现了本文模型的优越之处,并且这种分层分解还能更好地实现数据集之间的泛化,并提高区分细粒度语义差异的能力。
Introduction
传统的检索方法主要依赖于关键词搜索,但是,这些关键词受到限制并且不具结构化,不具备搜索细粒度内容的能力,如搜索“一只白色的小狗在追逐猫”这样的视频。
对于现行的视频-文本跨模态方法,可以分为两类:1)将视频和文本以嵌入的方式映射到全局向量中。尽管这种做法效率很高,但是这样的全局表示方法很难去捕获细粒度的语义信息。如图1所示,为了理解图中的视频和文本,需要对不同的行为和实体以及它们的组成部分进行复杂的推理(如“egg”是行动的接收者,而“break”和“into the cup”是动作方向);2)为了避免损失这些细节的损失,另一种方法使用一组帧和词分别表示视频和文本,并且对齐他们的局部组件(local components)来计算整体的相似性。尽管这样的方法在图像-文本检索中得到了很好的表现,但是将视频和文本进行语义对齐的难度比图像-文本要大很多,因为视频-文本对之间的有监督性比图像-文本要弱很多。此外,这样的顺序表示忽略了视频和文本中的拓扑结构,使得很难理解事件中局部组件之间的关系。

在本文工作中,使用了一种层次图像推理(HGR)模型,利用全局和局部的方法来弥补上面所述方法的不足。如图1所示,将视频-文本在三个语义层面上进行匹配,分别对应的是全局事件(global events)、局部动作(local actions)和实体(entities)。在文本方向,全局事件通过整个句子来表示,动作由动词表示,实体指名词短语。本文建立了一个跨级别的语义角色图(semantic role graph)来捕获事件中的局部组件如何合并的并且提出了一个基于注意力的图推理方法来生成分层文本嵌入。在每个语义层次使用跨模态来对齐以用于弱监督关系,将所有三个级别的匹配分数聚合在一起,以增强细粒度语义覆盖。
文章在三个视频-文本数据集上进行了大量的实验,最以前的方法不断改进证明本文提出的方法是很有用的。为了进一步评估细粒度检索的能力,本文还提出了一个新的二择任务:根据视频内容,对两个具有细微差距的句子进行选择最匹配视频内容的那个。主要贡献如下:
- 提出了一种层次图推理(Hierarchical Graph Reasoning,HGR)模型来进行细粒度视频-文本检索,具体做法为将视频-文本检索分到全局-局部的层次。这个模型,在全局匹配中利用了详细的语义,在局部层次利用了全局事件结构。
- 将文本进行了三个层面的分解(event,actions,entities),这三个层次通过注意力机制的图推理(attention-based graph reasoning)来交互并且在跨模态匹配时与视频对应的层次进行对齐。
- HGR模型在不同的视频-文本数据集上取得了改进的结果并且对不可见数据集有更好的泛化能力。一个新的二择任务进一步展示了本文提出的模型对于细粒度的区分能力。
Related Works
Image-Text Matching
很多先前的任务对于图像-文本匹配任务是将图像和句子作为在同一个latent空间中固定维度的向量来度量相似度。
Video-Text Matching
尽管与图像-文本匹配有相似处,但是视频-文本匹配任务更具有挑战性,因为视频包含多模态和时空演化(sptial-temporal evolution)。与本文工作较为接近的有两个:1)将行为短语分为动词和名词来进行细粒度的文本动作检索,但是这种方法无法应用于复杂句子的任务。2)将视频和段落进行层次的匹配,但是无法细化到具体的单个句子。
Graph-based Reasoning
图卷积网络(GCN)最早提出来对图中的节点的边进行卷积操作。图注意力网络(Graph attention network)进一步来对邻域特征进行动态的加入。为了进一步对图形不同的边进行建模,relational GCN被提出来对每一种关系类型学习其上下文的转换。在cv领域,图推理网络有很多应用,动作识别、场景图生成等任务。在这篇文章中,专注于推理分层图结构的视频描述细粒度视频文本匹配。
Hierarchical Graph Reasoning Model
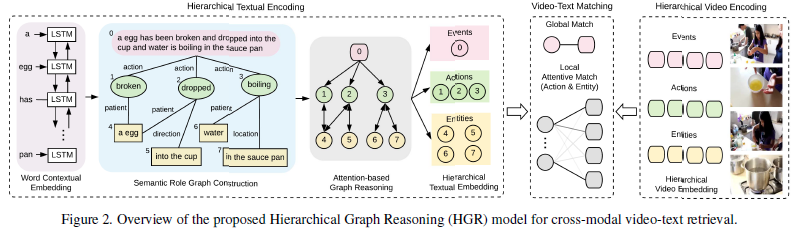
如图2所示,对于HGR模型分为三个部分:1)hierarchical textual encoding:包括文本中的角色语义图并且运用图推理区获取了层次化文本表示;2)hierarchical video encoding:将视频映射到对应的多层表示;3)video-text matching:在不同级别集合全局和局部进行根据跨模态相似性进行匹配计算。
Hierarchical Textual Encoding
视频描述包含了层次化的结构,整个句子描述了视频中的全局事件,它在时间维度上由多个动作组成,每个动作都由不同的实体组成,例如动作的施者和受者,这种全局到局部的结构有利于准确、全面地理解视频描述的语义。
Semantic Role Graph Structures
给定一个视频描述\(C\),包含\(N\)个词语\(\{c_1,\cdots,c_N\}\),将\(C\)认为是层次图中的全局event节点。文章中利用了一个现成的语义角色解析工具来获取句子中的动词和名词短语以及每个名词短语对应的动词。动词被认为是action节点,并且与event节点通过边直接连接,这样的话,不同动作的时序关系可以从图推理中的event节点中隐式学习。名词短语作为entity节点被连接到不同的action节点。从entity节点\(i\)到action节点\(j\)的边\(r_{ij}\)是由entity对action的语义角色决定的,而从action节点\(j\)到任何entity节点\(i\)的边\(r_{ji}\)为了简单起见统一为一个action类型。如果一个entity节点为不同的action节点服务多个语义角色,将为每个语义角色复制entity节点。这种语义角色关系对理解事件结构很重要,举个例子,”a dog chasing a cat“与”a cat chasing a dog”的区别只是交换了entity的位置。
Initial Graph Node Representation
本文将每个语义节点嵌入到稠密(dense)向量中作为初始化。对于event节点,旨在总结句子中描述的重点事件。首先使用双向LSTM生成一个上下文感知的词嵌入\(\{w_1,\cdots,w_N\}\),以下面的形式给出:

此处对\(w_i\)的值取前向与后向的值的均值。通过使用注意力机制将句子中的词嵌入作为全局event嵌入\(g_e\): \(g_e=\sum_{i=1}^N\alpha_{e,i}w_i\\ \alpha_{e,i}=\frac{\exp(W_ew_i)}{\sum_{j=1}^N\exp(W_ew_j)}\) 其中\(W_e\)是需要学习的参数。
对于action和entity节点,尽管可以使用不同的LSTMs来单独编码它们的组成词,语义角色分析可能会分离出有错误的单词,上下文单词表征有助于解决这些负面影响。由此,重新使用上面的Bi-LSTM词嵌入\(w_i\)并且在每个节点中的词使用最大池化,action节点表示为\(g_a=\{g_{a,1},\cdots,g_{a,N_a}\}\),entity节点表示为\(g_o=\{g_{o,1},\cdots,g_{o,N_o}\}\),\(N_a\)和\(N_o\)为对应的节点数。
Attention-based Graph Reasoning
使用跨层次的图结构不仅可以解释局部的节点怎么组成全局event,还可以减少每个节点的模糊性(ambiguity)。举个例子,图二中的实体“egg”可以在上下文中有不同的出现位置,但是动作“break”限定了“egg”的语义,所以这里的性状(visual appearance)应该是“broken egg”而不是“round egg”。所以,提出了在图交互上一种的一种推理方式来获取层次化的文本表示。
因为图中的边扮演了不同的语义角色,一个直接的方法去建模图中的交互就是使用relational GCN,对每个语义角色学习单独的transformation权重矩阵。但是,这样会导致参数的快速成长,这使得从有限的视频文本数据中学习效率低下,并且容易对罕见的语义角色进行过度拟合。
为了解决这个问题,文章将因子分解权重(factorize multirelational weights)应用到了GCN之中,分为两个部分:一个对所有关系类型都通用的转换矩阵\(W_t\in \mathbb R^{D\times D}\),一个对不同语义角色特定的角色嵌入矩阵\(W_r\in \mathbb R^{D\times K}\)(\(D\)是节点表示的维度,\(K\)是语义角色数量)。GCN的输入的第一层,将节点嵌入\(g_i\in \{g_e,g_a,g_o\}\)与它们的语义角色相乘(role awareness):\(g_i^0=g_i\odot W_rr_{ij}\),其中\(r_{ij}\)是表示节点\(i\)到节点\(j\)的独热编码。假设\(g_i^l\)是第\(l\)层第\(i\)个输出表示,对于这些表示使用一个图注意网络从相邻节点中选择相关的上下文去强化每个节点的表示: \(\tilde{\beta}_{ij}=(W_a^qg_i^l)^T(W_a^kg_j^l)/\sqrt{D}\\ \beta_{ij}=\frac{\exp(\tilde{\beta}_{ij})}{\sum_{j\in \mathcal N_i}\exp(\tilde{\beta}_{ij})}\) 其中,\(\mathcal N_i\)是节点\(i\)的邻居节点,\(W_a^k\)和\(W_a^q\)是来计算图注意力的参数。然后共享参数\(W_t\)被用来使用残差结构转换被关注的节点的上下文到节点\(i\): \(g_i^{l+1}=g_i^l+W_t^{l+1}\sum_{j\in \mathcal N_i}(\beta_{ij}g_j^l)\) 综合上面的式子,可以看出下层节点的转换对于不同的语义角色边是有针对性的。以第一层GCN网络为例: \(g_i^1=g_i^0+\sum_{j\in \mathcal N_i}(\beta_{ij}(W_t^1\odot W_rr_{ij})g_j)\) 这样一来,就可以将参数规模从\(L\times K \times D \times D\)降为了\(L\times D \times D+K \times D\)(残差结构)。层次化上下文表示就是GCN的第\(L\)的输出,用\(c_e\)表示全局event节点,\(c_a\)表示action节点,\(c_o\)表示entity节点。
Hierarchical Video Encoding
视频也有很多角度的信息,比如object(物体),actions(行为)和events(事件)。但是,直接将视频分析为层次结构是很困难的(需要时序段落,物体检测,物体追踪等)。本文建立了三个独立的视频嵌入来代替上面的各种角度的信息,来关注视频不同的角度。
给定视频\(V\)作为以一系列逐帧特征(frame-wise features)\(\{f_1,\cdots,f_M\}\),使用不同的权重\(W_e^v\),\(W_a^v\),\(W_o^v\)来将视频映射到三个不同层次的嵌入: \(v_{x,i}=W_x^vf_i,x\in\{e,a,o\}\) 对于全局event级别可以使用注意力机制(与文本的类似)来获得视频中的重点活动,编码为\(v_e\)。对于action和entity层次,视频表示分别为一系列逐帧特征\(v_a=\{v_{a,1},\cdots,v_{a,M}\}\)和\(v_o={v_{o,1},\cdots,v_{o,M}}\)。这些特征将被输入到下面的匹配模块,在不同的层次上与对应的文本特征进行匹配,这保证了在对应文本表示的指导下,可以学习不同的转换权值来关注不同层次的视频信息。
Video-Text Matching
与建立层次化表示类似,在进行文本-视频匹配时,也是在三个层次上进行匹配。
Global Matching
在全局event层面,视频和文本使用注意力机制被编码为全局向量来捕获视频中的重点语义信息。因此可以简单的使用余弦相似度来衡量全局层次上的跨模态相似性。全局匹配得分函数为\(s_e=cos(v_e,c_e)\)。
Local Attentive Matching
在action和entity层面上,视频和文本都有很多的局部组件构成。所以,需要衡量跨模态局部组件之间的对齐关系来计算匹配得分。对于每个\(c_{x,i}\in c_x,x \in \{a,o\}\),首先计算每对跨模态组件之间的相似性,这里使用余弦相似度:\(s_{ij}^x=cos(v_{x,j},c_{x,i})\)。这些局部相似性很显然直观的反映了文本中的节点与视频帧之间的相关性强度,但是它们缺少了适当的归一化。因此,受到栈注意力(stacked attention)的启发,对\(s_{ij}^x\)进行归一化: \(\varphi_{ij}^x={\rm softmax}(\lambda([s_{ij}^x]_+/\sqrt{\sum_j[s_{ij}^x]^2_+}))\) 其中\([\cdot]_+=\max(\cdot,0)\)。然后使用\(\varphi_{ij}^x\)在视频帧上当每个局部文本节点\(i\)动态对齐\(c_{x,i}\)时作为注意力权重,将经过增加权重的相似性结果相加,得到对于文本节点\(i\)的局部相似性:\(s_{x,i}=\sum_j\varphi_{ij}^xs_{ij}^x\)。最终将所有的文本结果合并,得到局部相似性:\(s_x=\sum_is_{x,i}\)。局部注意匹配不需要任何局部文本-视频基础,可以从弱监督的全局视频-文本对中学习。
Training and Inference
对多模态的相似性采取平均值: \(s(v,c)=(S_e+S_a+S_o)/3\) 使用contrastive ranking loss作为训练目标。对每一个positive的匹配对\((v^+,c^+)\),在mini-batch中找到最negative的nagetive匹配对\((v^+,c^-)\)和\((v^-,c^+)\),然后将它们与positive距离推的更远,如下式(\(\Delta\)是原先定义的margin): \(L(v^+,c^+)=[\Delta+s(v^+,c^-)-s(v^+,c^+)]_++[\Delta+s(v^-,c^+)-s(v^+,c^+)]_+\)
Experiments
为了展示HGR模型的高效性,将其在三个视频-文本数据集上进行文本-视频检索和视频-文本检索与SOTA进行比较。大量的消解实验也被用来研究模型的每一个组成部分是否有效。除此之外,文章还提出了一个二择任务来评估细粒度的跨模态检索任务。
Experimental Settings
Datasets
数据集MSR-VTT:包含了10000段视频和每段视频的20条文本描述。
数据集TGIF:包含了10w条gif格式的视频,每个视频有1-3条视频描述信息。
数据集VATEX:包含3.5w条视频数据,每个视频有10条用中英文写的句子(在实验中只使用英文句子)。
Evaluation Metrics
使用了一系列的检索通用度量方法,包括Recall at K(R@K),Median Rank(MedR)和Mean Rank(MnR)。R@K是在对结果rank后前k个结果正确率的衡量(文中使用K=1,5,10)。MedR和MnR分别度量检索到的排序列表中正确条目的中位和平均排名,得分越低表示模型越好。
Implementation Details
对于视频编码,文章使用了在Imagenet上预训练的Resnet152来抽取MSR-VTT和TGIF上的逐帧特征,在VATEX数据集上使用其官方提供的I3D视频特征。对于文本编码,文章设置了词嵌入规模为300并且使用Glove嵌入作为预训练。使用了两层的注意力图卷积,每层joint embedding空间为1024,在局部注意力匹配中设置\(\lambda=4\),对于训练中,设置边距(margin)\(\Delta=0.2\),模型训练50epoch,mini-batch为128,选择验证集上最好的epoch为结果。
Comparison with State of The Arts
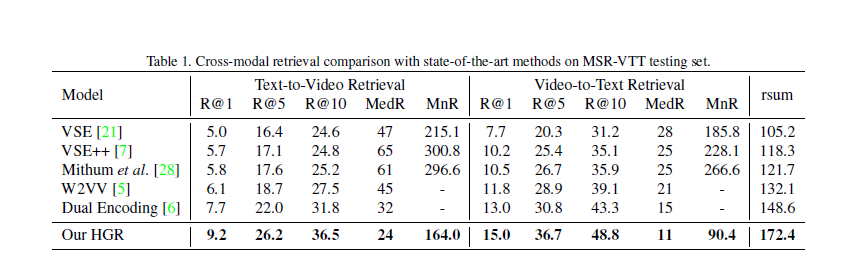
表1在MSR-VTT测试集上比较HGR与SOTA,为了公平起见,所有的模型都使用相同的视频特征,结果是超越了所有的SOTA。作者觉得主要原因是使用了全局到局部的匹配和带有注意力机制的图模型。
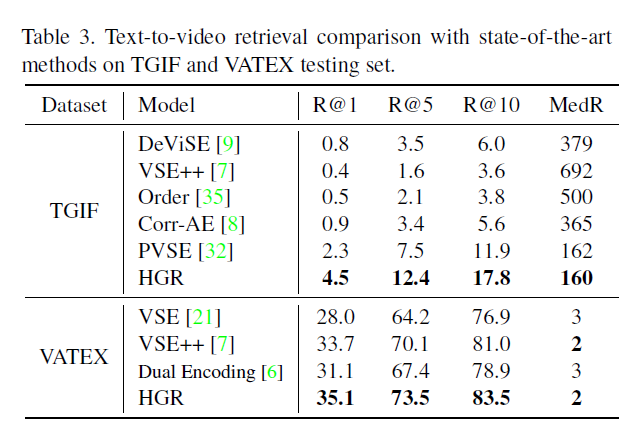
Generalization on Unseen Dataset
目前的视频-文本检索方法都是主要在同一个数据集上进行评估。但是,对于模型来说,将其泛化到域外数据是很重要的。所以作者更进一步的在一个数据集上进行训练然后在另一个数据集上进行评估。表2展示了在Youtube2Text数据集上的表现(使用MSR-VTT训练):

Ablation Studies
为了研究不同的部分对于模型的影响,在MSR-VTT数据集上设计了消融实验。
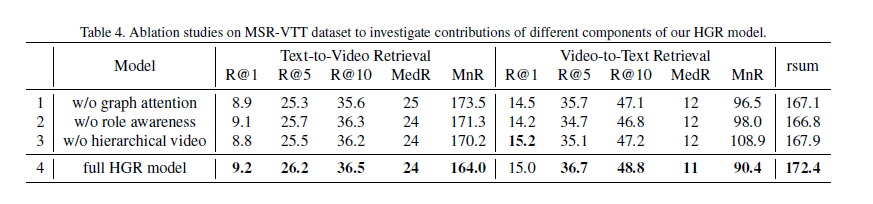
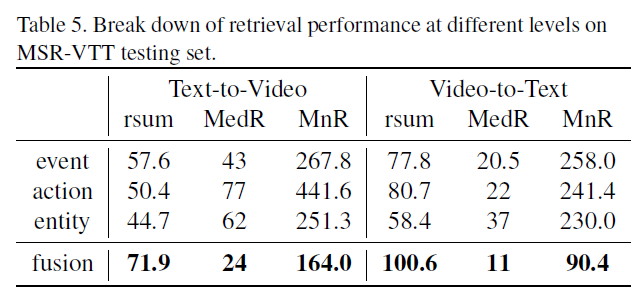
如表4所示,第一行除去了注意力机制,而是在邻居节点上使用简单的平均池化操作;第二行除去了role awareness,不再让语义角色通过event互相连接,在图3中,给出了如何在图推理的不同层中将action节点与邻居节点进行交互,在一层attention中,action节点“laying”和“putting”主要聚焦于其主要关注对象,例如“man”,然后第二层中,action节点开始对它们的时序关系进行推理,从而更加关注时间参数以及全局action节点的隐含上下文;第三行除去了层次结构,并在表5中展示了分别去除三个层次中一个的表现效果。

Fine-grained Binary Selection
为了证明本文模型在细粒度检索方面的能力,我们进一步提出了一个二元选择任务,要求模型从两个非常相似但语义上不同的句子中选择一个与给定视频更好匹配的句子。相较于positive的句子,对negative的句子做如下处理:
- 交换角色:将动作的实施者和接受者交换
- 替换动作:使用随机的动作替换句子中的动作
- 替换人群:使用随机的实体代替句子中的实体
- 替换场景:随机替换句子的场景
- 不完整的活动:只保留句子中部分动作和实体
表6显示了在不同二元选择任务上的效果。

Qualitative Results


Conclusion
大多数成功的跨模态视频-文本检索系统都是基于联合嵌入方法。但是,简单的嵌入并不足够能捕获复杂的视频和文本细粒度的语义信息,所以本文提出了一个层次化图推理模型(HGR),包括event,action和entities层面。然后,它通过基于注意力的图形推理生成分层的文本嵌入,并在不同层次上将文本与视频对齐。在三个视频-文本数据集上的实验结果表明了该模型的优越性。所提出的HGR模型在不可见数据集上也取得了较好的泛化性能,能够区分细微的语义差异。在之后的工作中,作者准备使用多模态和时空推理改进视频编码能力。

