SIGIR2019跨模态检索方法SDML
2020-09-16 Jay Saligia 21 mins 东湖之月
读《Scalable Deep Multimodal Learning for Cross-Modal Retrieval》
这篇论文是SIGIR2019的一篇论文,介绍了一种可拓展的跨模态检索深度学习方法(SDML)。现有的跨模态检索的方法大都是联合学习一个子空间,所有的模态在训练时都要被同时学习。本文提出的方法预先定义了一个公共子空间,这个子空间中使得组间差距最大化的同时组内差距最小,然后,对每个不同的模态训练一个特定的网络,将这些模态输入进预先定义的子空间,这样做的话就可以对不同的模态分别训练,而不是同时学习所有模态,并且也是第一个可以不固定模态输入数量的模型。
SDML简介
何为跨模态检索?跨模态检索指的是将一种模态的数据作为输入序列在另一种模态中寻找对应的数据,例如文本与图像的跨模态搜索。由于不同模态之间的异质性,直接计算不同模态内容之间的相似度是不可取的,所以跨模态检索的难点就在于如何高效的计算不同模态内容之间的相似性。
先前的利用深度学习的训练方法要将所有的模态进行联合训练,这就带来了两个问题:1)不能单独的训练学习特定模型的转换方法;2)整个模型在有新的模态加进来时,需要全部重新训练。论文提出的模型针对每个模态建立特定的网络来将其数据转换到相同的子空间,每个特定模态的网络包含了一个有监督的损失函数和一对编码解码器。设置有监督的损失函数是为了尽可能保留编码器在预设公共子空间中的分辨能力,每个特定模态的编码器堆放于对应的编码器之上来保持模态语义的一致性。这些特定模态的网络没有任何共享的参数,这就意味着这些网络可以并行训练。下图是对于SDML模型的概览,可以看到不同的模态并行训练后映射到同一公共子空间,在经过一个编码器之后,上面的路线是解码器,下面的路线是有监督的标签投影。
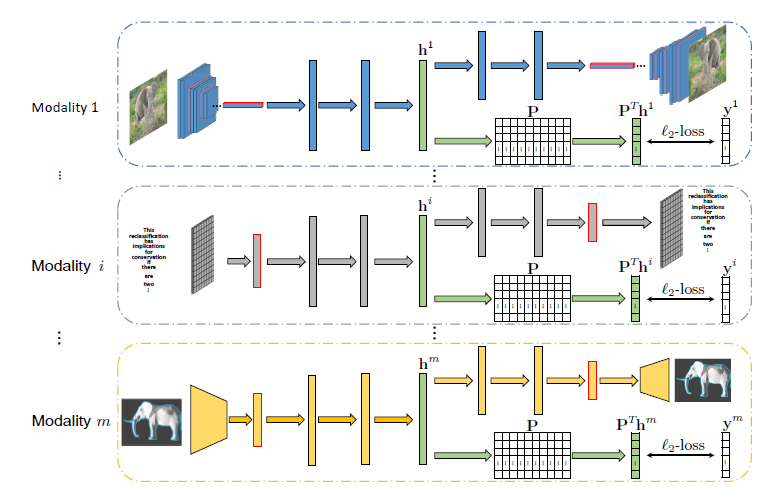
首先,先定义什么是多模态学习。假设\(m\)个模态中有一组数据,第\(i\)个模态的第\(j\)个样本记为\(x_j^i\),第\(i\)个模态的样本总数为\(n_i\),因此有集合\(\mathcal{X}_i=\{ {\rm x_1^i},{\rm x_2^i},\cdots,{\rm x}_{ni}^i \}\),对应的标签为\({\rm Y}_i=\left[{\rm y}_1^i,{\rm y}_2^i,\cdots,{\rm y}_{ni}^i \right]\),并且\({\rm y}_j^i=\left[y_{1j}^i,y_{2j}^i,\cdots,y_{cj}^i\right]^T\in\{0,1\}^c\)是语义标签向量,其中\(c\)是语义分类的总数。如果第\(i\)个模态中的第\(j\)个样本属于第\(k\)个分类,\(y_{kj}^i=1\),否则\(y_{kj}^i=0\)。多模态学习是为了学习不同模态特定的转换函数(transformation functions):\(f_i\left({\rm x}_j^i,\Theta_i \right)\in {\mathbb R}^d\),其中\(d\)是共同子空间中表示的纬度数,\(\Theta_i\)表示第\(i\)个特定模态转换函数中的可学习参数。通过转换函数可以将不同的模态转换到共同子空间,并且来自同一类的样本相似度比不同类的样本相似度更高,因此,在跨模态检索任务中,可以用一个模态的数据去检索另一个模态中相关的数据。
SDML给定一个固定的矩阵来预先定义一个公共子空间,使得特定模态的神经网络是独立的。这个固定的矩阵将样本的表示从公共子空间投影到标签空间,从而将监督信息转换到公共子空间来监督特定模态的网络的学习过程。为了满足这个目标,论文为每个模态设计了一个深度监督自编码器(DSAE)来将样本映射到公共子空间。DSAE是一层附加了有监督损失的表征层,从标签信息中推导的附加的监督损失可以尽可能的增加在预定义的公共子空间中辨识能力。
对于第\(i\)个网络的第\(j\)个样本的编码器记为\({\rm h}_j^i=f_i({\rm x}_j^i,\Theta_i)\),解码器记为\({\rm \hat{x}}_j^i=g_i({\rm h}_j^i,\Phi_i)\),设计的DSAE目标函数为: \({\mathcal J}^i=\frac{1}{n_i}\sum_{j=1}^{n_i}\left[\lambda{\mathcal J_r^i({\rm x}_j^i)+(1-\lambda){\mathcal J_s^i({\rm x}_j^i)}} \right]\\ =\frac{1}{n_i}\sum_{j=1}^{n_i}\left[\lambda\|{\rm \hat x}_j^i-{\rm x}_j^i\|_2+(1-\lambda)\|{\mathbf P^T}h_j^i-{\rm y}_j^i\|_2 \right]\) 其中\(\lambda\)是平衡参数,\(\mathbf P\)是预定义公共子空间的矩阵。在整个算法中,\(\mathbf P\)起到至关重要的作用,假设矩阵\(\mathbf P\)有\(u\)行\(v\)列,那么\(u\)应等同于编码器输出的单元数,\(v\)应等同于语义分类的个数,此处将\(\mathbf P\)设计为一个正交矩阵,这使得不同类别的一维子空间是相互正交的,增加了预定义子空间的辨别力。
在多模态学习中,要同时解决两个问题,一个是最小化目标函数: \({\rm min}\mathcal J^i\ {\rm for}\ i\in\{1,2,\cdots,m \}\) 一个是求解模态的转换方程。在求解中,可以通过随机梯度下降来寻求最优解。
算法细节
对于每个模态的网络都由7个全连接层构成,并且每个全连接层之后跟着一个ReLU单元作为中间层。\(\mathbf P\)矩阵是随机生成的列正交矩阵。在测试时,不使用解码器并且编码器的姐u共作为样本的一般表示。在跨模态检索中,使用表示间的余弦距离作为相似度衡量标准。

对于SDML的优化算法具体如上图,算法的输入为所有模态的训练数据集\(\mathcal X_1,X_2,\cdots,X_m\),对应的标签\({\rm Y_1,Y_2,\cdots,Y}_m\),矩阵\(\mathbf P\),表示空间维度\(d\),一次训练样本数\(n_b\),学习率\(\alpha\)和超参\(\lambda\)。输出为最优权重\(\Theta_1,\Theta_2,\cdots,\Theta_m\)。算法具体实现如下:
- 随机生成初始化参数\(\Theta_1,\Theta_2,\cdots,\Theta_m\)(编码器)和\(\Phi_1,\Phi_2,\cdots,\Phi_m\)(解码器)。
- 在每个训练步中,首先随机选出第\(i\)个模态中\(n_b\)个样本作为mini-batch,然后使用前向传播计算每个样本的编码结果\({\rm h}_j^i\)和解码结果\({\rm \hat x}_j^i\),接着使用目标函数计算第\(i\)个模态的loss,最后使用随机梯度下降来更新\(\Theta_i\)和\(\Phi_i\),具体公式为:\(\Theta_i\leftarrow\Theta_i-\alpha\frac{\partial \mathcal J^i}{\partial\Theta_i};\Phi_i\leftarrow\Phi_i-\alpha\frac{\partial \mathcal J^i}{\partial\Phi_i}\)。
实验
论文一共在四个数据集上进行了训练和测试,分别是PKU XMedia、Wikipedia dataset、NUS-WIDE dataset和MS-COCO dataset。
文章中具体说明了在PKU XMedia数据集上的使用的数据。PKU XMedia包含了5000段文字、5000张图片、1143条视频、1000条音频片段和500个三维模型。对于图片数据,每张图片在ImageNet上预训练,由7层全连接AlexNet生成4096维特征向量;对于文本数据,使用3000维的词袋特征作为文本特征向量;对于视频,使用在Sports-1M上预训练的C3D模型生成4096维向量;对于音频向量,使用29维MFCC特征;对于3D模型,使用LightFiled描述集合中的4700维向量。
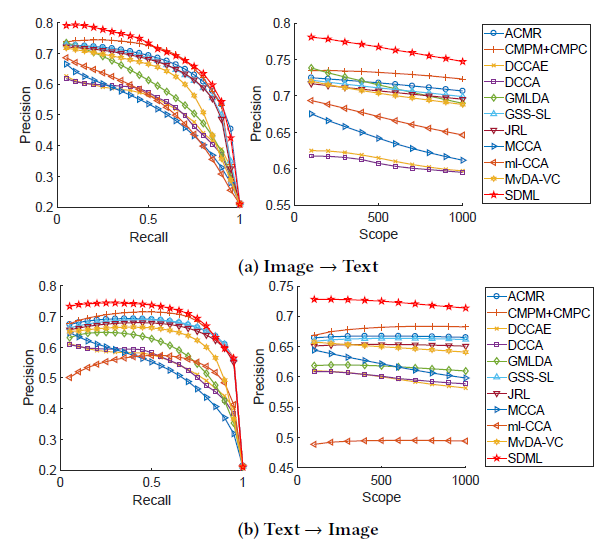
从下图中可以看出,在跨模态检索任务\(\rm Image\rightarrow Text\)和\(\rm Text\rightarrow Image\)中,SDML模型都超越了之前模型的表现效果。

在Wikipedia dataset上的模型表现对比
在NUS-WIDE dataset上的模型表现对比

在MS-COCO dataset上的模型表现对比
总结
论文提出的SDML模型是一个可以独立并行学习每个模态转换网络的跨模态检索模型,模型一共包含三个部分:多个独立特定模态编码器、对应的解码器和一个预先定义的标签投影。自动编码器帮助模型提取底层特征,以便于准确预测每个模态,预先定义的标签投影将所有模态投影到共同的子空间。相较之前的模型,可以独立并行的训练,可以在原训练的基础上方便地扩展模态并且在多个数据集上的表现优于先前的跨模态检索模型。
论文中表示下一步的工作将聚焦于对更贴近实际使用的没有预先标注分类的数据进行跨模态检索。

