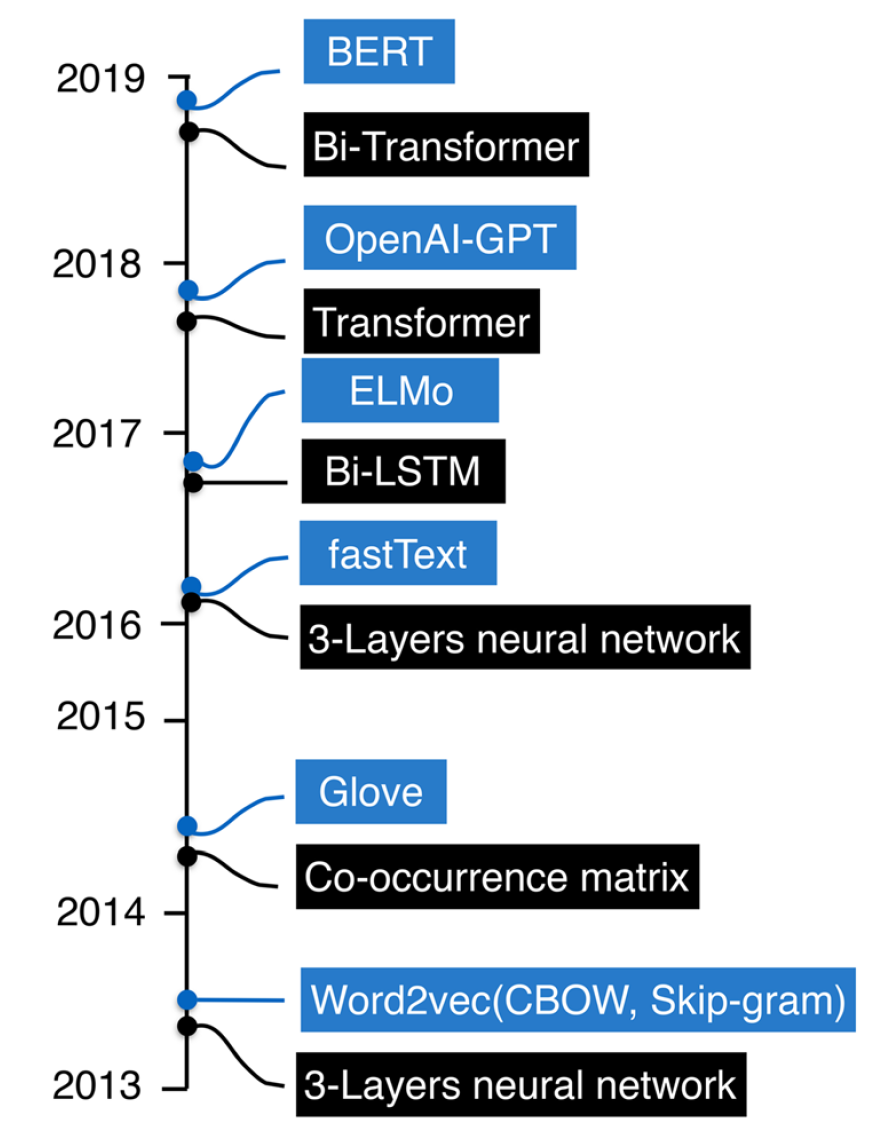
词向量表示技术概览
2021-07-13 Jay Saligia 48 mins 云:我裂开了
词向量表示技术概览
词向量表示技术是利用向量表示词语的技术,广泛的应用于NLP的下游任务之中,以向量形式捕捉词汇语义和处理词语的抽象意义,只有转换为向量形式才能用于进一步的语义计算。然而,大多数模型的表达语义受到语料库中每个词的上下文分布的限制,而逻辑和常识却没有得到更好的利用。
本文基于《A survey of word embeddings based on deep learning》和其他资料
distributional hypothesis
“一个词观其伴而知其意“ Firth
Harris提出出现在相同的上下文中的词语具有相似的语义,分布式假说是统计语义学的基础。
经典方法
Language model
语言模型指预测一个序列的概率大小的模型。
假设每个单词都是独立的: \(p(w_1,w_2,\cdots,w_n)=\prod_{i=1}^np(w_i)\) 假设每个单词生成概率都是由之前的所有单词决定的: \(p(w_1,w_2,\cdots,w_n)=\prod_{i=1}^np(w_i\vert w_{i-n+1},\cdots, w_{i-1})\)
n-gram语言模型基于马尔可夫假设,根据依赖的程度分为几类:
不依赖于任何词语(unigram): \(\begin{align*} p(S) &= p(w_1,w_2,w_3,\cdots,w_n)\\ &= p(w_1)\times p(w_2)\times p(w_3)\cdots p(w_n) \end{align*}\) 依赖于前面出现的一个词(bigram): \(\begin{align*} p(S) &= p(w_1,w_2,w_3,\cdots,w_n)\\ &= p(w_1)\times p(w_2\vert w_1)\times p(w_3\vert w_2)\cdots p(w_n\vert w_{n-1}) \end{align*}\) 依赖于前面出现的两个词(trigram): \(\begin{align*} p(S) &= p(w_1,w_2,w_3,\cdots,w_n)\\ &= p(w_1)\times p(w_2\vert w_1)\times p(w_3\vert w_2,w_1)\cdots p(w_n\vert w_{n-1},w_{n-2}) \end{align*}\)
one-hot
对于每个词语使用一个向量表示,该向量中只有一个维度为1,其余均为0,独热编码没有考虑任何上下文的信息,并且面临数据稀疏的问题。
BOW
词袋模型是一种对文本中词的表示方法。该方法将文本想象成一个装词的袋子,不考虑词之间的上下文关系也不关心词语在袋子中存放的顺序。在独热编码的基础上,文档中某一维度对应的是该词语出现的次数。 \(Rome=[1,0,0,0,0,0,\cdots,0]\\ Paris=[0,1,0,0,0,0,\cdots,0]\\ Italy=[0,0,1,0,0,0,\cdots,0]\\ France=[0,0,0,1,0,0,\cdots,0]\\ \\ doc_1=[32,14,1,0,\cdots,6]\\ doc_2=[2,12,0,28,\cdots,12]\\ \cdots\ \cdots \\ doc_3=[13,0,6,2,\cdots,0]\) BOW也是TF-IDF算法的基础。
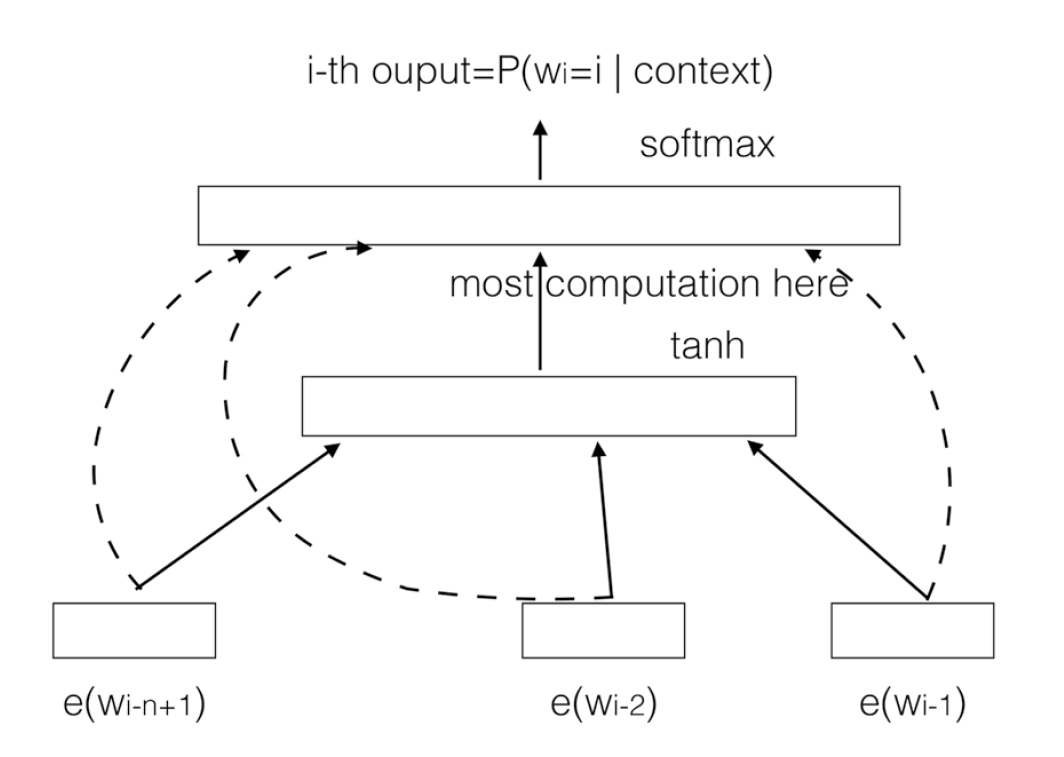
Neural network language model(NNLM)(2003)
NNLM在进行语言模型训练时把词嵌入作为产出。与语言模型类似,NNLM使用前\(n-1\)个词语预测第\(n\)个词语,但与语言模型不同的是NNLM使用神经网络来预测而不是使用联合概率。
NNLM使用了一个三层结构的网络,输入是序列\(w_{i-n+1}, w_{i-n+2},\cdots,w_{i-1}\)的词嵌入拼接顺序:
\(x=[e(w_{i-(n-1)});\cdots;e(w_{i-2});e(w_{i-1})]\)
使用\(x\)来预测输出结果:
\(h=tanh(b^{(1)}+Hx)\\
y=b^{(2)}+wx+Uh\)
LSA(Latent Semantic Analysis)(1998)
LSA把词语和文档都映射到一个潜在语义空间。将文档集构造一个Term-Document矩阵\(M\),矩阵中每个位置的值\(M_{ij}\)表示第\(i\)个词在第\(j\)个文档中的词频、TF-IDF或者其他类似的值。对\(M\)进行奇异值分解: \(M=USV^T\) 对SVD分解的结果进行降维,只保留\(S\)前\(k\)个最大的奇异值得到\(S^\prime\),对\(U,V\)进行同样操作,得到\(U^\prime,V^\prime\),即为每个文档在潜在语义空间上的\(k\)维表示。

使用降维后的矩阵重建Term-Document矩阵,\(M^\prime=U^\prime S^\prime V^{\prime T}\)。\(M^\prime\)的每行可视为每个词语的词向量,每列可视为每个文档的文档向量
对于一个列向量表示的新文档\(Q\),其在潜在语义空间上的\(k\)维表示为:\(Q^\prime=Q^TU^\prime S^{\prime -1}\)


-
LSA无法捕捉一词多义的现象。在原始词-向量矩阵中,每个文档的每个词只能有一个含义。比如同一篇文章中的“The Chair of Board”和”the chair maker”的chair会被认为一样。在语义空间中,含有一词多意现象的词其向量会呈现多个语义的平均。相应的,如果有其中一个含义出现的特别频繁,则语义向量会向其倾斜。
-
LSA具有词袋模型的缺点,即在一篇文章,或者一个句子中忽略词语的先后顺序。
-
LSA的概率模型假设文档和词的分布是服从联合正态分布的,但从观测数据来看是服从泊松分布的。因此LSA算法的一个改进PLSA使用了多项分布,其效果要好于LSA。
Word2Vec
推荐阅读:Word2vec Parameter Learning Explained
CBOW(2013)
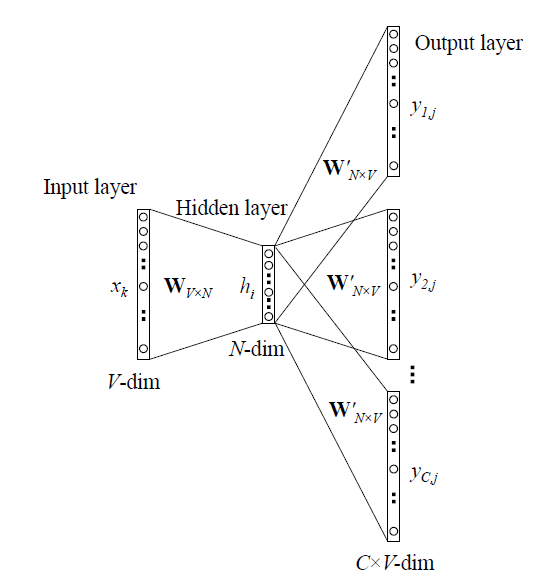
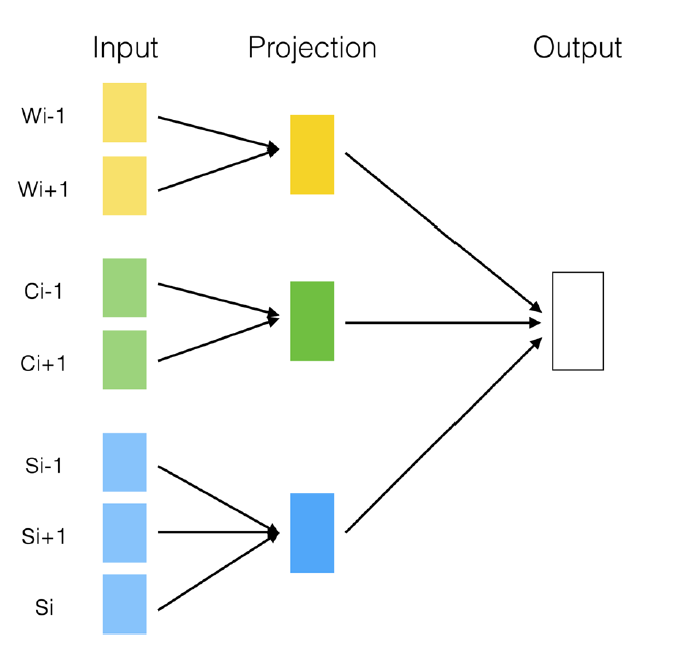
全称为Continuous Bag-of-Word Model。在我看来,CBOW和Skip-Gram都是在one-hot基础上加入了上下文的语义信息。
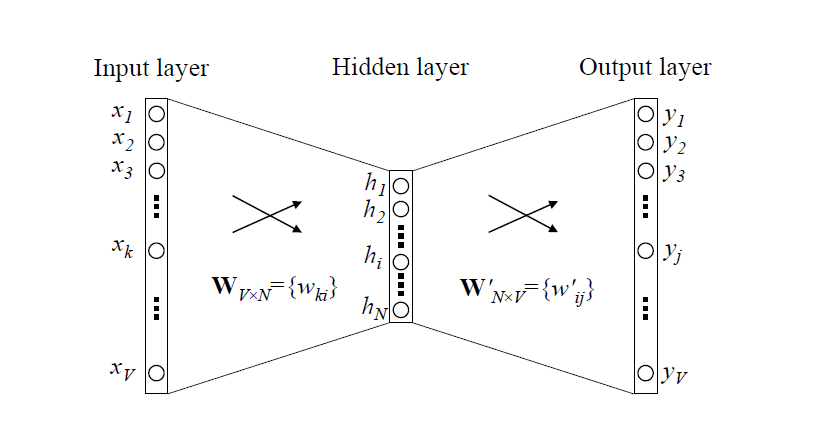
上图是CBOW最简单的形式,假设每个上下文只有一个词语。输入层为该词语的独热编码,\(W\)存储了每个词语的hidden向量,即通过矩阵乘法得到第\(k\)个词语(也就是独热码中第\(k\)位为1)的h向量,这一步完成了对于独热码的降维。从隐藏层到输出层有另一个矩阵\(W^\prime\),通过这个矩阵为词典中每个词语计算得分,也就是在输入的上下文的基础上,下一个单词的概率。将上下文只有一个单词推及到有多个单词,得到CBOW的一般形式:
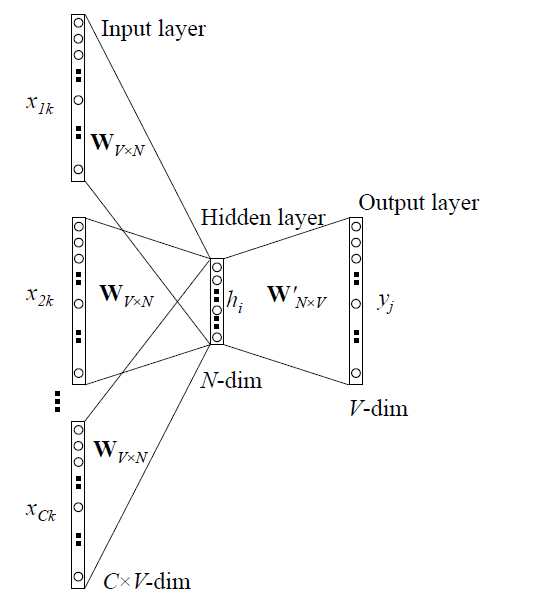
在一般形式中,取多个输入得到的h向量的平均值作为h向量。另外,值得注意的是,由CBOW模型得到的词向量一般取输入之后的h向量。
Skip-Gram(2013)
与CBOW类似,skip-gram也是利用独热编码作为输入然后得到h向量,但与CBOW不同的是skip-gram使用的是通过一个词语来预测上下文,也就是说,输出是上下文,输入是目标单词。由于输出权重都是\(W^\prime\),输出\(C\)个单词预测的结果(\(C=2 * skip\_window + 1\))的分布,结果应该是一样的,在此基础上进行损失值的计算。
Glove(2014)
Glove的提出用来解决Word2vec只关注于局部语义信息,而忽视了全局统计信息的问题。Glove是基于全局共现矩阵的,每个矩阵中的元素\(X_{ij}\)表示词向量\(w_i\)和\(w_j\)在特定上下文中出现。\(P_{ij}=P(j\vert i)=\frac{X_{ij}}{X_i}\)是\(w_j\)出现在\(w_i\)上下文的概率。要做的事情就是如何利用词嵌入的向量表示中蕴含了共现概率矩阵中的关系,即给定词语\(i,j,k\),它们具有\(r=\frac{P_{ik}}{P_{jk}}\)的关系,那么Glove需要找到一个函数\(F\)使得它们的词向量之间也有这个关系: \(F(w_i,w_j,w_k)=\frac{P_{ik}}{P_{jk}}\) 为了建立这个联系,通过一系列演变,最终得到\(F\)和损失函数 \(F(w_i,w_j,w_k)=\frac{P_{ik}}{P_{jk}}\\ F(w_i-w_j,w_k)=\frac{P_{ik}}{P_{jk}}\\ F((w_i-w_j)^Tw_k)=\frac{P_{ik}}{P_{jk}}\\ exp(w^T_iw_k-w^T_jw_k)=\frac{exp(w^T_iw_k)}{exp(w^T_jw_k)}=\frac{P_{ik}}{P_{jk}}\\\) 由此,这个问题可以进一步转换为另一个问题,即: \(exp(w^T_iw_k)=P_{ik},exp(w^T_jw_k)=P_{jk}\) 又可以将三个词语之间的问题变成两个词语,只需要在全语料库中考察: \(exp(w^T_iw_k)=P_{ik}\\ w^T_iw_k=log(X_ik,X_i)=logX_{ik}-logX_{i}\) 现在有个问题,共现关系不应该是对称的,即交换\(i,k\),上式左边无变化,但右边会发生变化,因此引入偏移量,于是得到损失函数: \(J=\sum_{ik}(w^T_iw_k+b_i+b_k-logX_{ik})^2\) 根据经验,如果两个词出现共现次数越多,那么在损失函数中影响就会越大,因此加入一个权重: \(J=f(X_{ik})\sum_{ik}(w^T_iw_k+b_i+b_k-logX_{ik})^2\\ f(x) = \left \{ \begin{aligned} & (\frac{x}{x_{max}})^a & ,x<x_{max} \\ & 1 & ,otherwise \end{aligned}\right.\) 根据经验,取\(x_max=100\),\(\alpha=0.75\)。
OOV(out-of-vocabulary)
下列方法都是用来解决如何表示出现在词典之外的词语。对于OOV的词语,主要分为四种类型:
- 新出现的通用词语
- 专有名称
- 专业名词和研究领域名称
- 其他术语(新产品、新电影、新书等等)
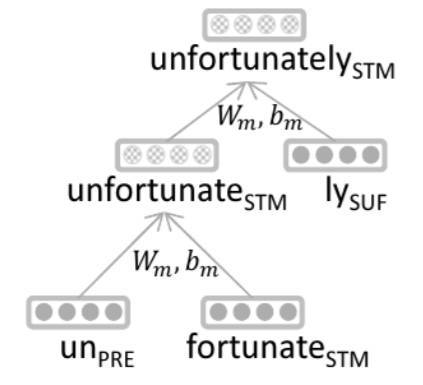
MorphoRNN(2013)
morphoRNN通过语素水平而不是单词水平对单词进行建模。具体来说,morphoRNN认为语素是自然语言的最小单位,为每个语素分配了一个不同的向量。通过用循环神经网络(RNN)训练词缀获得子词表示,并通过所有语素获得父词的嵌入。
FastText(2016)
FastText是一个基于CBOW的文本分类器,词嵌入是fastText的产物。大部分现存的词嵌入方法都是给每个词语分配一个独特的向量(atomic token),这是一个局限性,特别是对于由子词级信息组成的语言来说。fastText使用n-gram信息来获取词语之间的信息。
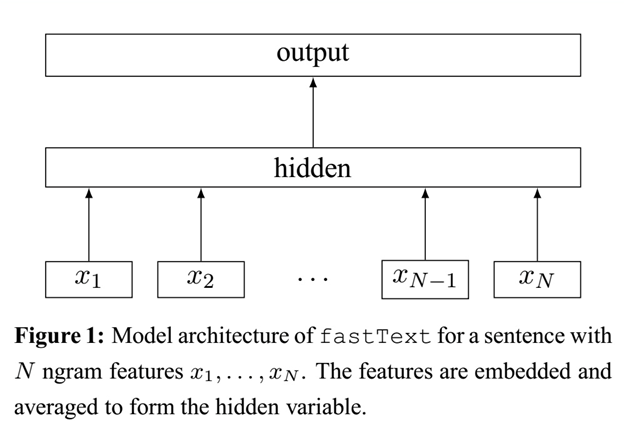
在fastText中,每个词语被分为若干个子词,例如对于单词“apple”的trigram为:\("<ap","app","ppl", "ple","le>"\)(\(“<“,”>“\)为标注词语界限的符号),这样做的好处有:
-
对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
-
对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
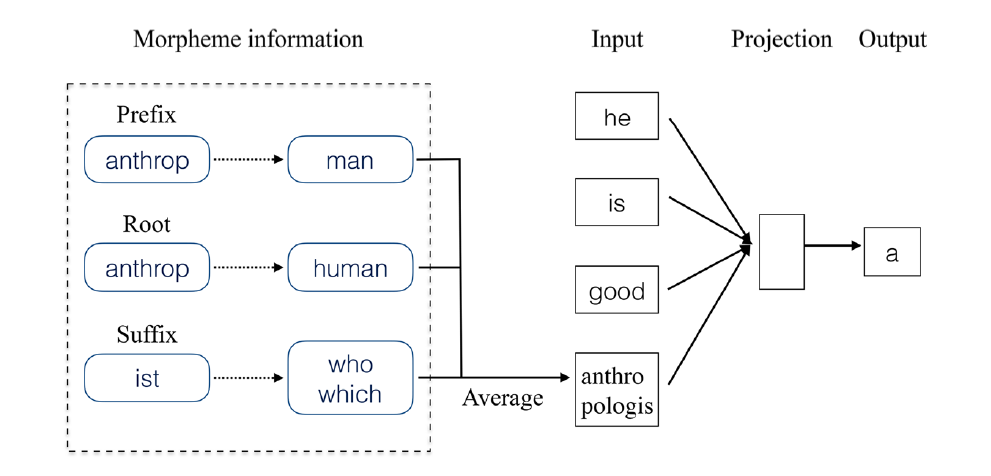
Mwe(2017)
Mwe的想法来自于表示词语的前缀和后缀。这个模型建立在这样的假设上,某个token的词素的意义对于该词表示的贡献是一致的。假设有一系列token\(W=\{w_1,w_2,\cdots,w_n\}\),假设\(w_i\)的词素意义的集合为\(M_i\),\(M_i\)可以分为三个部分:\(P_i,R_i,S_i\),分别对应前缀表意集合,词根表意集合,后缀表意集合。于是,对于\(w_i\)的上下文\(w_j\),优化过的\(w_i\)可以定义为 :
\(w_i=\frac{1}{2}(w_i+\frac{1}{N}\sum_{t\in M_i}t)\)
基于上下文嵌入
ELMo(Embeddings from Language Models)(2018)
一个好的词语表示应该考虑两个方面:1)能够反映出语义和语法的复杂特征;2)能够准确的对不同上下文进行反映。这种算法的特点是,每个词的表示是整个输入语句的一个函数。ELMo使用了双向LSTM语言模型,有一个前向和一个后向语言模型组成,目标函数就是取这两个方向上语言模型的最大似然。对于前向语言模型:
\(p(t_1,t_2,\cdots,t_N)=\prod_{k=1}^Np(t_k\vert t_1,t_2,\cdots,t_{k-1})\)
后向语言模型:
\(p(t_1,t_2,\cdots,t_N)=\prod_{k=1}^Np(t_k\vert t_{k+1},t_{k+2},\cdots,t_N)\)

假设输入的token是\(x_k^{LM}\),在每一个位置\(k\),每一层LSMT都输出对应的context-dependent的表示\(\overrightarrow{h}_{k,j}^{LM},j=1,2,\cdots,L\),\(L\)表示LSTM的层数,顶层的LSTM输出\(\overrightarrow{h}_{k,L}^{LM}\),通过softmax来预测下一个\(token_{k+1}\)。
对数似然函数表示如下:
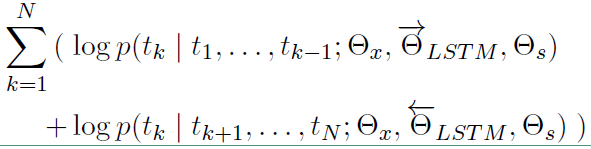
ELMo 模型不同于之前的其他模型只用最后一层的输出值来作为word embedding的值,而是用所有层的输出值的线性组合来表示word embedding的值,对于每个token,一个\(L\)层的biLM要计算出\(2L+1\)个表示:
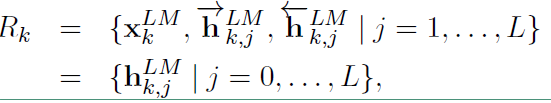
此时得到的是一个矩阵形式的词表示,在下游任务中将其压缩为一个向量(加权求和):
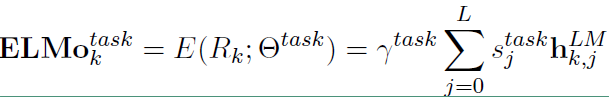
ELMO的使用主要有三步:
- 在大的语料库上预训练 biLM 模型。模型由两层bi-LSTM 组成,模型之间用residual connection 连接起来。而且作者认为低层的bi-LSTM层能提取语料中的句法信息,高层的bi-LSTM能提取语料中的语义信息。
- 在我们的训练语料(去除标签),fine-tuning 预训练好的biLM 模型。这一步可以看作是biLM的domain transfer。
- 利用ELMO 产生的word embedding来作为任务的输入,有时也可以即在输入时加入,也在输出时加入。
OpenAI-GPT(Generative Pre-Training)(2018)
与很多模型一样,GPT也通过语言模型生成词向量。在GPT中使用具有自注意力机制的Transformer编码器,在前向传播网络中,输入为输入文本和额外的位置信息,输出是词语的概念化分布: \(h_0=UW_e+W_p\\ h_l=Transformer_block(h_{l-1})\\ p(u)=softmax(h_nW_e^T)\)
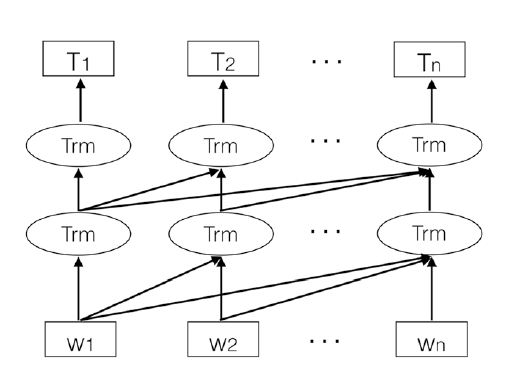
BERT(Bidirectional Encoder Representations from Transformers)(2018)
bert中使用了双向的transformer对语言编码,输入向量组成部分为token嵌入、段嵌入、位置嵌入。
token嵌入使用了WordPiece,将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡,例如将“playing”拆分为“play”和“ing”。
位置嵌入将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。
段嵌入用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。

下图是手绘的bert结构详解:

值得注意的是bert的训练思路与word2vec的CBOW类似,利用上下文的词语来预测中间词;GPT的训练思路和NNLM一样,利用语言模型预测下一个词语。
中文词向量
现在很多的中文词向量表示是直接从英文迁移过来的,它们将每个字或每个词作为atomic token。与英语不同的是,汉字的表达是二维的,传递信息的效率最高。此外,中文是以字为基础的,而不是以词为基础的,每个词通常由较少的字符组成,但可以传达丰富的语义信息。
CWE(character-enhanced word embedding model)(2015)
CWE利用内部字符和外部语境的优势,提取词语的每个字符,为它们分配嵌入,然后将字符嵌入和单词嵌入结合起来,作为基于CBOW的模型的输入。定义语素为语言中的最小意义单位,词为语言中的最小表现单位。因此中文中的词大致可以分为两类,其一是单语素词,如“沙发”等音译词;其二是多语素词,由多个语素构成的词,如“红日”。

在文字中不可避免的会遇到一词多义的情形,CWE给出了三种解决方案:
-
Position-based Character Embedding
这种方案中,将汉字出现在词语中的位置分为:Begin,Middle,End这三种情况,也就是每一种汉字具有三种表示,这种方式比较简单,但是缺点也是比较明显的,它假设的前提是同一个汉字只要位于不同单词的同一个位置就具有相同的语义,这显然在一些情况下是不成立的。
-
Cluster_based Character Embedding
这种方案中,使用k-means的思想,为每个汉字预先分配\(x\)个子向量(模式向量),代表潜在定义的每个汉字所对应的语义模式,利用目标汉字的上下文窗口中的词语组成的语境向量,从一个汉字的所有模式向量中选择一个和上下文语义计算上最相似的作为该汉字对应的向量。
-
Nonparametric Cluster_based Character Embedding
与2中的方案类似,不同的是每个汉字预先分配的子向量数量是由学习而来。具体来说开始为每个汉字分配较少的模式向量,在训练过程中设置一个模式向量与语境向量的相似度阈值,当小于阈值的时候就说明当前该字所有的模式向量都不能表示该语境下的该字,此时新增一个新的模式向量。
SCWE(similarity-based character-enhanced word embedding model)(2016)
虽然CWE已经考虑了词的内部构成,增加了语义信息的表示,但它忽略了每个词和它们的组成部分(单字)之间的一些问题。CWE认为字和字之间的贡献是一致的,SCWE认为这种贡献应该是不一样的。假设\(x_t\)是\(W\)的构成词,在SCWE中: \(\widehat{v_{x_t}}=\frac{1}{2}\{v_{x_t}+\frac{1}{N_t\sum_{k=1}^{N_t}sim(x_t,c_k)v_c} \}\) 其中,\(v_{x_t}\)是\(x_t\)的嵌入,\(N_t\)是\(x_t\)中字符的数量,\(c_k\)是\(x_t\)中第\(k\)个词语。在此之上,SCWE提出了一种方案(SCWE+M)去解决歧义问题: \(\widehat{v_{x_t}}=\frac{1}{2}\{v_{x_t}+\frac{1}{N_t\sum_{k=1}^{N_t}sim(x_t,c_k)v_{ck}^i} \}\)
JWE(Joint Learning Word Embedding)(2017)
使用联合学习,学习中文中的word,character和更加细粒度的subcharacter。
对于word,指的是汉语中的词语。
对于character,指的是单个字。
对于subcharacter,每个字可以分为表意部分和表音部分,对于表意部分,例如“氵”与之相关的均与水相关;对于表音部分,例如包含“马”的很多字“吗”“码”等,读音均与“马”接近。
cw2vec(2018)
通过观察中文字符内部组成,发现中文字符包含偏旁部首、字符组件,笔画信息等语义信息特征。cw2vec采用笔画信息作为特征,由于每个字符包含很多的笔画,类似于一个英文单词包含很多的拉丁字母,在这个基础之上提出了笔画的n-gram特征。
以“大人”为例,第一步,将中文词语分割为单个字符,以获得中文字符的笔画信息,“大人”分割为“大”和“人”。第二步,获取中文字符的笔画信息,并且把笔画信息合并,“大”:一ノ丶,“人”:ノ丶,“大人”:一ノ丶 ノ丶。第三步,笔画信息数字化,用数字代表每一种笔画信息(文中一共有5中),就有:“大人”\(\rightarrow\)一ノ丶 ノ丶\(\rightarrow\)13434。第四步,提取词语笔画的n-gram信息,3-gram:134,343,434;4-gram:1343、3434;5-gram:13434。
之后的训练中即以词语的n-gram笔画特征信息代替词语进行训练,模型与CBOW类似。
