预训练下的改良NLU
2020-11-17 Jay Saligia 29 mins 桌子一角
读《Improving Language Understanding by Generative Pre-Training》
自然语言理解任务(NLU)包含了一系列的任务,包括文本蕴含、问题回答、语义相似度评估和文本分类。尽管大量的无标签文本语料库被抛弃了,对以上所提及的任务的有标签数据还是很少的,这就使得对这些有针对性的训练任务想达到很好的效果是很难的。在这些任务中,可以通过在不同的语料集的训练生成语言模型(generative pre-training)然后对每个特定任务有针对性的调优(discriminative fine-tuning)。与先前的方法不同,本文在调优时使用了一种任务级(task-awre)的输入转换在需要对模型结构做最小的变化的基础上进行transfer。
Introduction
在NLP中,从原始数据中能够高效学习是缓解对于有监督学习依赖的关键。深度学习任务需要大量的有标签数据,但是在某些领域这些数据是贫乏的,这就导致这些深度学习方法的应用性较差。在以上的情境中,模型可以通过使用无标签数据中的语言信息(linguistic information)来收集更多的annotation,但是这种方法费时费力。更近一步讲,即使有监督任务中样本很多,但是通过无监督方式学习到一种好的表示(representation)往往会带来显著的表现改善。一个例子就是在NLP中大量使用预训练模型的词嵌入来改善模型的表现。
从无标签数据中获取超越词语级别的信息主要有两个困难的地方。第一个,在训练时不知道哪个优化目标用来做transfer是有效的;第二个,将学习到的表示迁移到目标任务的最有效方式还没有产生共识。现有的方式需要以下几种方法的混合:对模型结构做特定任务的改变,使用复杂的学习方法和增加辅助学习目标。这些不确定性导致很难对语言处理建立起有效的半监督学习方法。
本文提出了一种半监督的方式来处理语言理解任务:使用无监督的预训练和有监督的调优方式。这种方式的目标是为了学习一种在迁移到各类下游任务中只需要做很少的适应性调整的通用表示(universal representation)。假设可以获取一个有大量无标签文本的语料库和几个目标任务的有人为标记的训练样例,在算法设置时,不要求目标任务和无标签语料库在同一个领域中。算法的训练过程分为两个阶段:第一个阶段,在无标签数据上使用语言建模目标来学习神经网络的初始参数;第二个阶段,使用相应的有监督目标将这些参数适应于目标任务。
在模型结构上,使用Transformer模型,Transformer模型在解决长期依赖的问题上提供了一个更结构化的记忆结构(与循环网络相比),这就使得在迁移到不同的模型的时候具有更强的鲁棒性。在迁移时,使用从traversal-style派生的方法来适应特定任务的输入(将结构化的文本以单一连续的token序列输入),后续的实验证明这样可以在调优时对预训练模型做最小的调整。
在实验设计上,本文在四类NLU任务上进行了评估:自然语言推断、问题回答、语义相似和文本分类。
Related Work
NLP半监督任务
早期的NLP半监督任务使用未标注数据来计算词语级别或短语级别的数据,之后在有监督任务中当成特征使用。当越来越多的NLP任务使用了词嵌入技术后,发现这对于NLP任务的训练效果确实很有用。与之前只关注于词句级别的特征不同,本文的目标是去捕获更高层次的语义信息。
无监督预训练
无监督预训练是半监督学习的一种特殊情况,其目标是找到一个好的初始化参数,而不是优化有监督学习的目标。早期的无监督任务主要应用于图像分类和回归任务,后续研究表明,预训练可以作为一种正则化方案,在深度神经网络中具有更好的泛化效果。与本文最接近的工作是使用语言建模目标对神经网络进行预训练,然后在有监督下对目标任务进行调优。
辅助训练目标
使用添加辅助的无监督训练目标是半监督学习的另一种形式,在以往的研究中,学者加入例如POS标记、分块、命名实体识别和语言模型等辅助NLP任务去改善无监督训练效果。本文也采取了辅助训练目标,但无监督预训练已经学习到了几个目标任务的语言概念。
Framework
训练过程分为了两个阶段。第一个阶段在大规模文本语料库上学习一个大规模的语言模型,第二个阶段是调优阶段,将任务迁移到带有标注数据的特定模型。
无监督预训练
给定一个无监督语料库的token集合\(\mathcal U=\{u_1,\cdots,u_n\}\),使用一个标准的语言模型目标去优化下面这个似然函数: \(L_1(\mathcal U)=\sum_i \log P(u_i|u_{i-k},\cdots,u_{i-1};\Theta)\) 其中\(k\)是上下文窗口的大小,条件概率\(P\)是使用神经网络(参数为\(\Theta\),通过随机梯度下降训练)。
在本文中,对语言模型使用多层Transformer解码器。这个模型在输入的上下文token中使用一个多头(multi-head)自注意操作,然后通过位置上的前馈层去产生目标token上的输出分布: \(h_0=UW_e+W_P\\ h_l=transformer\_block(h_{l-1})\forall i\in[1,n]\\ P(u)=softmax(h_nW_e^T)\) 其中,\(U=(u_{-k},\cdots,u_{-1})\)是上下文token向量,\(n\)是层数,\(W_e\)是token嵌入矩阵,\(W_P\)是位置嵌入矩阵。
有监督调优
在经过无监督预训练之后,将参数应用到有监督目标任务中。给定一个有标签的数据集\(\mathcal C\),其中每个实例包含了一组输入token序列,\(x_1,\cdots,x_m\)和对应的标签\(y\),输入通过预训练模型之后得到了最终的trasformer单元的激活结果\(h_l^m\),然后加入到一个参数为\(W_y\)额外的线性输出层去预测\(y\): \(P(y|x^1,\cdots,x^m)={\rm softmax}(h_l^mW_y)\) 同样,给定一个最大似然函数作为优化目标: \(L_2(C)=\sum_{(x,y)}\log P(y|x^1,\cdots,x^m)\) 通过增加语言模型作为在调优时的辅助目标在两个地方是很有用的:1)改善有监督模型的泛化能力(正则化);2)加速收敛。因此,加入语言模型的优化目标为(\(\lambda\)为权重): \(L_3(C)=L_2(C)+\lambda*L_1(C)\)
总的来说,唯一需要微调的参数就是\(W_j\)和嵌入的分隔符token。
特定任务输入transformation
对于某些任务,例如文本分类,可以直接用上面的模型进行调优。本文中使用了一种traversal-style的方法,将结构化的输入转换成一个有序的序列,使得预训练模型可以处理。如下图所示,给出了这些输入的transformation的描述:图左边给出了transformer的结构和训练目标,图右边给出了对于不同的任务进行的微调。将所有结构化的输入转换为token序列,由预先训练好的模型处理,然后是线性+softmax层,所有的transformations包含了增加的随机初始token和结束token\((<s>,<e>)\)。

文本蕴含
(上图右二)对于文本蕴含任务,将前提(premise)\(p\)和假设(hypothesis)\(h\)token通过定界符\((\$)\)连接起来。
相似性
(上图右三)对于相似性任务,两个要被比较的句子本身没有固定的顺序,为了反应这个特征,将输入序列包含两种可能的输入顺序(用定界符来连接),并且独立的去生成两个句子的表示\(h_l^m\),在输入到线形层前对这两个表示逐项相加。
问题回答和常识推理
(上图右四)对于这些任务,给定一个文档\(z\),一个问题\(q\),和一组可能的回答\(\{a_k\}\),将这些连接起来,得到token序列\([z;q;\$;a_K]\),每个序列都独立的经过本文模型处理,并且通过softmax归一化最终得到可能的回答的输出分布。
Experiments
设置
无监督预训练
使用BooksCorpus数据集来训练语言模型(包含7000本未出版的图书,包含主题有冒险、幻想和言情)。重要的是,这个数据集有大段连续的文本,这使得可以通过生成模型来学习大范围信息的状况。
特定模型
本文训练了一个12层的只有解码器的带有masked自注意力头的transformer(有768个维状态和12个注意力头)。对于位置牵制网络,使用3072维的内部状态(inner states)。使用Adam优化方法(最大学习率设为2.5e-4),将学习率从0线性地在前2000步增加到最大值并使用余弦值来逐渐下降到0。
训练规模:minibatches=64,epochs=100,tokens=512。
因为layernorm在整个模型中都广泛使用了,权重初始化设置为\(N(0,0.02)\)就足够了。本文使用了40000个字节对编码(BPE)词汇表和残差(residual)、嵌入(embedding)和注意力dropout(以0.1的比率)合并来用于正则化。同样也使用了一个优化的L2正则化方案。对于激活函数,使用高斯错误线性单元(Gaussian Error Lineaer Unit,GELU)。
调优细节
除非需要对模型特化处理,超参的设置与无监督预训练一致。对于分类器,增加了一个dropout率为0.1的分类器。对于大部分的任务,设置学习率为6.25e-5,batchsize规模为32.因为调优速度很快,训练epoch设置为3就足够了。
有监督调优

上图给出了将模型用于不同任务时所使用的数据集。
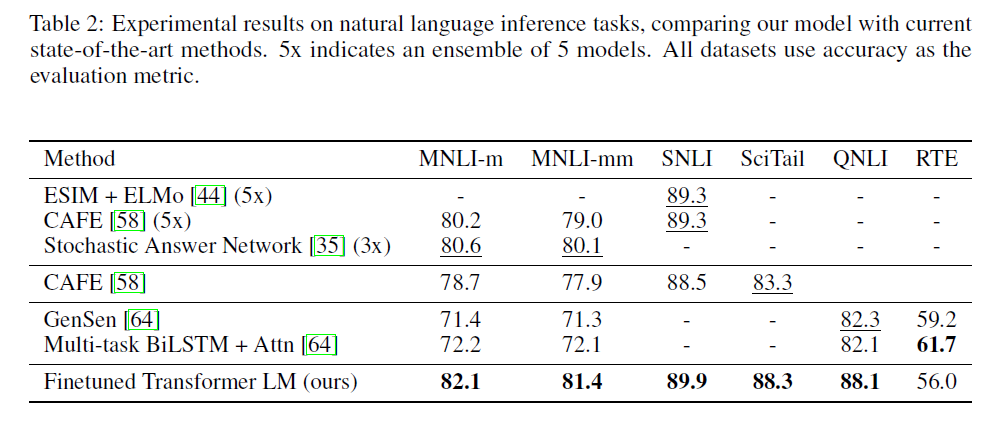


总体来说,本文的方法在12个数据集中的9个胜出了并且在不同大小的数据集上表现都很好。
分析
被迁移层数的影响
在实验中,作者发现从无监督预训练迁移到有监督目标的网络层数对实验结果是有影响的。

如上图所示,随着使用预训练模型中层数的提高,各类模型上的表现效果也在提高,这就说明与训练模型中的包含有效信息的每一层对于解决下游任务都是有用的。
zero-shot行为
最好要弄清楚为什么预训练模型会有效?一种假设是,与LSTMs相比,潜在生成式模型(underlying generative model)在应用到很多任务时可以提高语言建模的能力并且transformer更具结构化的注意力记忆(attentional memory)有助于迁移。如下图所示,作者设计了一系列启发式的方案,在不使用有监督调优的情况下使用潜在生成式模型。可以观察到这些启发式算法的性能是稳定的,并且在训练中稳步增长,这表明生成式训练支持学习各种各样的任务相关功能。还可以观察到LSTM在零样本性能上表现出更高的方差,这表明transfer结构的inductive bias有助于transfer。
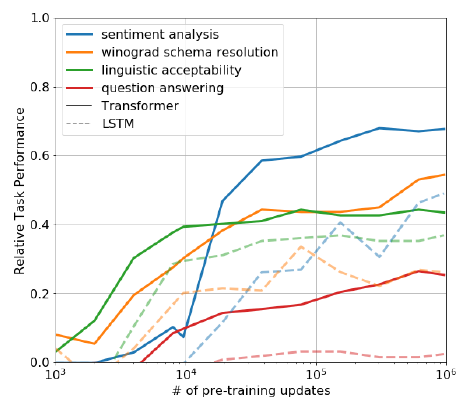
对于CoLA(linguistic acceptability):将生成式模型分布的token的对数概率平均值作为分数并且通过阈值来预测。
对于SST-2(sentiment analysis):对每个例子增加\(very\)token并且限制模型的输出仅有\(positive\)和\(negative\)。
对于RACE(question answering):根据模型结果的token的平均对数概率最高值作为回答问题的结果。
对于DPRD(winograd schemas):用两个可能的说法来替换已有的两个代词,在这之后通过平均对数概率预测剩余的序列。
Ablation studies

对本文模型采取三种ablation方案。第一,测试了在调优时不加入辅助LM目标训练的情况,发现在NLI任务和QQP任务上辅助训练任务是有效的,总的来说,更大的数据集可以从辅助目标中收益,但小的数据集不会。第二,在同样的模型中使用单层有2048个单元的LSTM替代Transformer,发现有5.6分的差距,LSTM仅在MRPC数据集上表现优于transformer。第三,直接在有监督目标上训练(跳过预训练),发现和有预训练有14.8%的差距。
Conclusion
通过在有连续长文本的语料库上进行的预训练,模型得到了重要的世界知识(world knowledge)和处理长期依赖的能力,之后将预训练模型迁移到解决特定任务中去(包括问题回答、语义相似、文本蕴含和文本分类),最终的结果表明在12个数据集上有9个数据集取得了效果的提升。本文研究表明,使用transformer和使用有长期依赖的数据集对ML结果的改善是很有用的。
