STRUCTBERT
2020-11-17 Jay Saligia 28 mins 可爱猫猫
读《STRUCTBERT:INCORPORATING LANGUAGE STRUCTURES INTO PRE-TRAINING FOR DEEP LANGUAGE UNDERSTADING》
依托于Elman的线性化方法,通过将语言结构融入到预训练,将BERT拓展为了新的模型:StructBERT。特别的是,使用两个辅助任务去预训练StructBERT以充分利用单词和句子的顺序(在单词和句子级别利用语言结构)。
Introduction
在文本语义相似度、问题回答和情感分类等NLU领域中,预训练的语言模型(LM)是一个重要的组成部分。为了获取有效的语言表示,本文设计了神经语言模型来定义具有自监督学习的文本中单词序列的联合概率函数。与传统的对每个token给定一个全局表示的特定单词的embedding不同,近来很多模型(Cove、ELMo、GPT和BERT)从在大型文本语料库上训练的语言模型中获取上下文化(contextualized)的词向量。在很多下游任务中证实这类模型很有效。
在上下文敏感的语言模型中,BERT已经席卷NLP领域。它的目的是预先训练双向表示法,通过联合条件作用于所有层的左右上下文,并仅通过上下文预测掩蔽词来建模表示法,然而,它并没有充分利用底层语言结构。
通过Elman的研究,循环神经网络对简单句子的时序规律很敏感。既然语言流利度是由单词和句子决定的,在许多NLP任务中,如机器翻译和NLU,寻找一组单词和句子的最佳排列是一个基本问题。Schmaltz表明,具有长短期记忆的循环神经网络语言模型,即使没有任何明确的句法信息,cell也能有效地进行词排序。
在本文中,作者介绍了一种新的上下文表示的方法,StructBERT,使用两种线性化策略将语言结构包含进了BERT模型。具体来说,除了现有的masking策略之外,StructBERT还通过利用结构信息扩展了BERT:单词级排序和句子级排序。本文分别在句子内结构和句子间结构上增加了两个新的结构目标,通过这种方式,预训练过程中可以准确的捕捉到语言信息。
通过结构化的预训练,StructBERT在上下文表示中将单词和句子进行编码,使得模型有更好的普遍性和适应性。
本文有以下两个主要贡献:
- 提出了基于BERT拓展的结构化的预训练模型,将词结构化目标和句结构化目标融入了上下文的表示中。这使得StructBERT能够通过硬性重构单词和句子的正确顺序来显式地为语言结构建模,从而实现正确的预测。
- StructBERT在广泛的NLU的任务上都取得了比现有论文更好的结果。该模型扩展了BERT的优势,在语义文本相似度、情感分析、文本蕴涵和问题回答等语言理解应用中提高了性能。
StructBERT Model Pre-training
给定一个文本句子或一对文本句子,BERT将它们打包成一个token序列,并为每个token学习上下文化的向量表示。每个输入token都基于单词、位置和它所属的文本段来表示。下一步,将每个输入向量输入进双向Transformer块的栈之中,并且使用整个输入序列的自注意力来计算文本表示。
与原始的BERT的模型相比,StructBERT通过在单词掩蔽后打乱一定数量的token并预测正确的顺序来增强掩码语言模型任务的能力。为了更好的理解句子之间的关系,StructBERT随机交换句子的顺序并预测之后的和之前的句子作为新的句子预测任务。这样,新模型不仅能显式地捕捉每个句子中的细粒度单词结构,而且还能以双向的方式对句子间结构进行恰当的建模。在使用两个辅助任务训练完成之后,可以在广泛的下游任务中进行调优。
Input Representation
每个输入\(x\)是一个由单词token组成的序列,序列既可以是一个句子,也可以是组合在一起的一对句子,输入表示的形式与BERT一样。对每个输入token\(t_i\),通过相应的token嵌入、位置嵌入和段嵌入来计算它的对应表示\(\mathbb x_i\)。通常会增加一个特殊的分类嵌入(classification embedding,[CLS])作为序列开头的token,一个特殊的结尾嵌入(end-of-sequence,[SEP])作为每一个段结尾的token。
Transformer Encoder
使用多层双向Transformer编码器来对编码输入表示的上下文信息。给定输入向量\(\mathbf X=\{\mathbf x_i\}_{i=1}^N\),一个L层的Transformer的对输入的编码形式如下: \(\mathbf H^l=Transformer(\mathbf H^{l-1})\) 其中,\(l\in[1,L],\mathbf H^0=\mathbf X,\mathbf H^L=[\mathbf h_1^L,\cdots,\mathbf h_N^L]\),这里使用隐向量\(\mathbf h_i^L\)作为输入token\(t_i\)的上下文化表示。
Pre-training Objectives
为了充分利用语言中丰富的句内结构和句间结构,我们对原BERT的训练前目标进行了两种延伸:词结构目标(主要用于单句任务)和句子结构目标(主要用于句子对任务)。预先训练这两个辅助目标和原始的掩蔽LM目标在一个统一的模型中寻找内在的语言结构。
Word Structural Objective
尽管在很多NLU任务中BERT都取得了成功,但是原始的BERT无法显式地对自然语言中单词的序列顺序和高顺序依赖性(high-order dependency)进行建模。给定一个句子中随机顺序的一组单词,理想情况下,一个好的语言模型应该能够通过重建这些单词的正确顺序来恢复这个句子。
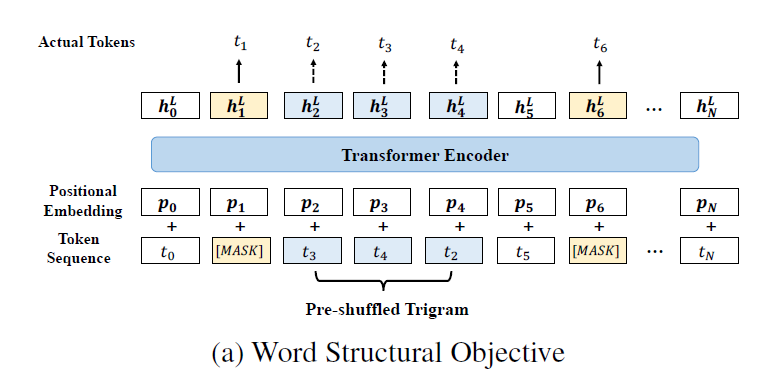
上图给出了联合训练新单词目标和掩码语言模型目标的方法。对每个输入序列,首先像BERT一样,随机的将15%的token进行遮掩,将由双向Transformer编码器计算出的掩码对应的输出向量\(h_i^L\)送入softmax分类器,对原始的掩码进行预测。接下来,单词目标考虑新词的顺序,给定随机打乱的token,单词目标相当于将每个打乱的token放置在正确位置的可能性最大化。更正式的说法可以将目标定为如下形式: \(\arg\max_\theta \sum \log P(pos_1=t_1,pos_2=t_2,\cdots,pos_K=t_K|t1,t2,\cdots,t_K,\theta)\) 其中,\(\theta\)表示StructBERT中可训练的参数,\(K\)表示每个被打乱的子序列的长度。从技术上讲,一个更大的\(K\)将迫使模型能够重建更长的序列,同时注入更多的干扰输入;相反的是,当\(K\)越小时,模型得到的未干扰序列越多,恢复长序列的能力越弱。最终决定取\(K=3\)来平衡模型的可重塑性与鲁棒性。
具体的说,如图所示,随机的选择未遮掩的token中一定的连续三个token,打乱它们的顺序(如打乱了\(t_3,t_4,t_2\)),由双向Transfer编码器计算的打乱token的输出向量,然后送入softmax分类器来预测原始token。新单词预测目标与掩码语言模型预测目标在一个统一的预训练模型中等权共同学习。
Sentence Structural Objective
原始BERT模型对于预测下一个句子很有效(97%-98%的正确率)。在StructBERT中,不仅要预测下一个句子还要预测上一个句子,使得预训练语言模型以双向的方式感知句子的顺序。
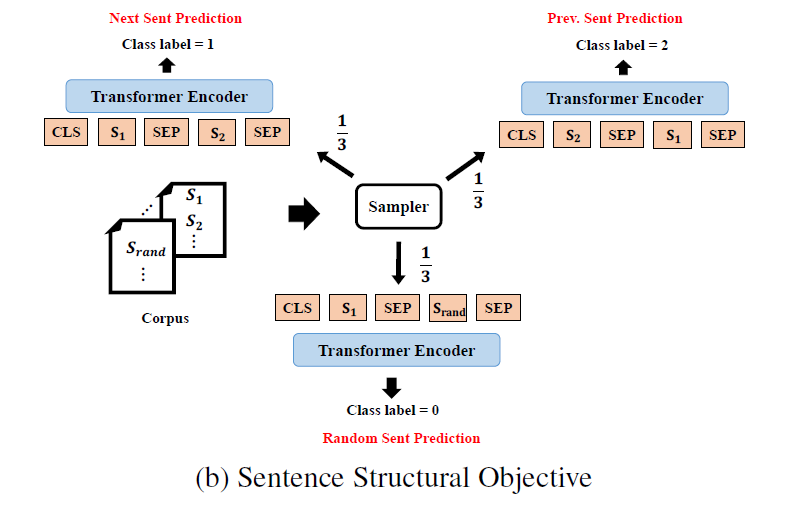
如上图所示,给定一对句子\((S_1,S_2)\)作为输入,预测\(S_2\)是\(S_1\)的下一条句子还是\(S_1\)的上一条句子,抑或是不同文本中的随机句子。具体来说,对于句子\(S_1\)有三分之一的概率为\(S_2\)的前一句,有三分之一的概率为\(S_2\)的后一句,有三分之一的概率与\(S_2\)无关。像BERT一样用\([SEP]\)token连接两个句子,本模型中取第一个\([CLS]\)对应的隐藏状态,将模型输出进行池化,并将\([CLS]\)的编码向量输入softmax分类器进行三类预测。
Pre-training Setup
训练目标函数是单词结构目标和句子结构目标的线性组合。对于掩码语言模型目标函数,设置与BERT保持一致,5%的三元词被选中来做随机打乱。
从English Wikipedia和BookCorpus中选择文档作为预训练数据,做到输入序列长度设为512。
设置学习率为1e-4,\(\beta_1=0.9\),\(\beta_2=0.999\),\(L_2\)权重衰减0.01,总步骤的前10%的学习率预热,随后对学习率的线性衰减。对每一层设置dropout率为0.1,与GPT一样,使用GELU作为激活函数。
设定Transformer层数为\(L\),隐藏向量规模为\(H\),自注意力头数量为\(A\),在BERT的实践之上,设计了两个不同规模的实验模型: \({\rm StructBERTBase}:L=12,H=768,A=12,{\rm Number\ of\ parameters=110M}\\ {\rm StructBERTLarge}:L=24,H=1024,A=16,{\rm Number\ of\ parameters=340M}\\\)
Experiments
使用StructBERT在应用于一系列下游任务,包含通用语言理解评估(General Language Understanding Evaluation,GLUE benchmark)、斯坦福自然语言推断(Standford Natural Language inference,SNLI corpus)和抽取问题回答(extractive question answering,SQuAD v1.1)。
按照BERT的做法,在对下游任务进行微调时,对以下参数集执行网格搜索或穷举搜索(取决于数据大小),并选择在开发集上性能最好的模型,其他参数与预训练模型中的保持一样。
General Language Understanding
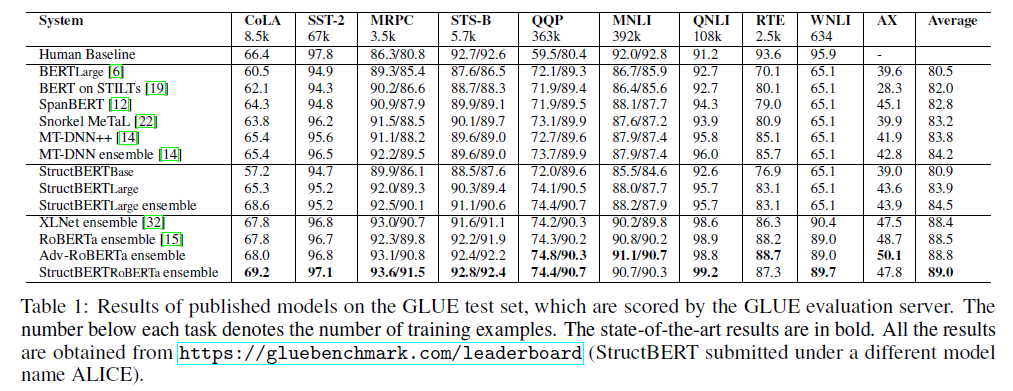
GLUE benchmark
GLUE基准包含9个NLU任务,包含文本蕴含(RTE和MNLI)、问答蕴含(QNLI)、释义(MRPC)、问题解释(QQP)、文本相似度(STS-B)、情感分析(SST-2)、语言可接受性(CoLA)和Winograd Schema(WNLI)。
SNLI
自然语言推断(NLI)是自然语言理解中一个重要的任务,这个任务的目的是测试模型推理两个句子之间的语义关系的能力。为了更好地执行NLI任务,模型需要捕捉句子的语义,从而推断出一对句子之间的关系:隐含关系、矛盾关系或中性关系。

Extractive Question Answering
这个任务的目标是从一个问题的相应段落中提取出正确的答案。SQuAD v1.1是一个包含了100000+问题的数据集。可以看到没做任何数据增强时,StructBERT在Dev数据集上已经超过了出XLNet外的所有方法

Effect of Different Structural Objectives
为了证实两种辅助训练的结构目标是有效的,采取了ablation(消解)方法来验证,即每次只使用一个结构目标来进行预训练。

实验中还给出了与BERT进行的loss与accuracy的对比。

Related Work
Contextualized Language Representation
一个词根据它的上下文可以有不同的语义。ELMo使用两个基于LSTMs的单向语言模型,一个LM从前向后阅读文本,一个LM从后向前阅读文本。OpenAI GPT使用大量的语料库和多层Transformer解码器并使用从左到右的Transformer做文本序列预测。BERT模型使用双向Transformer编码器去融合左右的上下文。
Word & Sentence Ordering
线性化的目的是恢复打乱的句子的原始顺序。近来,Transformer在很多潜在语言结构中的任务都被证实是很有效的。
Conclusion
本文提出了一种新的结构预训练方法,它将单词和句子结构整合到BERT预训练中。为深入理解不同粒度的自然语言,本文提出了单词结构目标和句子结构目标两个新的预训练任务,实验结果表明StructBERT可以将很多下游任务的效果提高到目前最好的效果(GLUE,SNLI,SQuAD v1.1)。
