实体关系抽取综述
2019-12-05 Jay Saligia 121 mins 一眼珞珈山
实体关系抽取 Relation Extraction : A Survey
update:2019.12.5
update:2019.12.6
update:2019.12.9
update:2019.12.11
update:2019.12.13
update:2019.12.15
简介
信息抽取(information extraction,IE)是从给定的文本库中以结构化的形式(如XML)输出特定的信息。
一般而言,信息抽取的对象有三类
(1)命名实体(named entities)
(2)关系(relations)
(3)事件(events)
一个关系通常就是指一个两个或更多NE间良定的(有意义的)关系。
RE面临着很多挑战
(1)域和域(domain-to-domain)之间有非常多的可能存在的关系,而且有很多非二元关系
(2)有监督的机器学习技术缺乏充分的训练数据
(3)关系本身的定义就是模糊不清的
(4)关系的表示是依赖于语言的,所以RE也是依赖于语言的
Global level 和 mention level
Global RE system期望产生一组存在特定语义关系的实体对,输入是有大量文本的语料库,输出是一组实体对。
Metion RE system是将实体对和包含这一实体对的句子作为输入,然后辨别这一实体对中是否有特定的关系。(也成为关系探测和描述(Relation Detection and Characterization,RDC))
示例
Obama is visiting India today.可以识别出,Obama和India之间是PHYS关系
Obama likes India’s culture.无法识别出Obama和India中的关系

RE技术分类
(1)有监督的方法,包括features-based和kernel based
(2)将实体抽取和关系抽取组合的方法
(3)半监督的方法
(4)无监督的方法
(5)开放信息抽取(Open Information Extraction)
(6)远程监督技术(distant supervision based techniques)
(7)其他先进技术
有监督方法
有监督方法需要关系被打上标签的二元实体对。其中用NONE标签来标注预定义中没有的标签,简单来说,有监督方法就是一个分类问题。
基于特征方法 Feature-based Methods
基于特征的方法,对于每个被标注的实体关系会产生一组特征和一个分类器(或一组分类器),然后经过训练去对新的关系进行分类。
有一些附加的特征被加入进来用来改善RE结果。
Word based features(基于词法特征)
Base phrase chunking based features(基于句法特征)
Features based on semantic resourses(基于语义资源)
用core tree去代表任意的关系,core tree不止包含两个实体在依存树中的最短路径并且包含额外的链接节点和句中关键词的最短路径,core tree的子树被用来挖掘其中的特征。
有一种方法将所有的关系类型表示成几种有限制的句法语义结构。
Premodifier:用来修饰其他名词的形容词或专有名词(Indian minister)
Possessive:第一个实体是所有格的(Italy’s government)
Preposition:两个实体是通过介词连接的(governor of RBI)
Formulaic:两个实体被写成某些特殊形式(Mumbai,India)
有监督方法的一个主要问题是类别不平衡Class Imbalance,因为反面的实例(无意义的实体对)的数量远远大于正面的实体对,这就导致了分类器的高正确率但是低召回率。
一旦特征被设计好了,基于特征的方法就可以简单的通过机器学习方法来训练分类器。但是特征的设计需要大量的分析语言现象中潜在知识。
核方法 Kernel Methods
核方法的主要优势就是不需要非常清晰的特征工程,在核方法中,核函数被设计来计算两个关系实例中所用的表示形式间的相似性并且使用SVM来做分类。不同的核采用了不同的关系实例的表示方法(序列化,句法分析树等),按照这些表示方法的子表示方法中相同的部分来衡量相似性。
序列化核 Sequence Kernel
用序列来表示关系实例并且核计算两组序列中共享的子序列。受到字符串序列的启发,有一种最简单的转换为序列的方法,就是考虑句子中的第一个到第二个词。不把每个句子成分当成单独的单词,将每个词推广为一个特征向量。每个关系实例就变成了一组特征向量的序列。这些特征以下几个方面生成
\(\sum\nolimits_1\):Set of all words
\(\sum\nolimits_2\):Set of all POS tags = {NNP, NN, VBD, IN, \(\dots\)}
\(\sum\nolimits_3\):Set of all generalized POS tags = {NOUN, VERB, ADJ, ADV, \(\dots\)}
\(\sum\nolimits_4\):Set of entity types = {PER, ORG, LOC, GPE, \(\dots\)}

序列化示例
每组序列化的特征向量是\(\sum\nolimits_X=\sum\nolimits_1\times\sum\nolimits_2\times\sum\nolimits_3\times\sum\nolimits_4.\)目的是要设计一种核函数可以找到这些被共享的子序列\(\mathcal u\)(属于空间\(\sum\nolimits_U^*=\sum\nolimits_1\cup\sum\nolimits_2\cup\sum\nolimits_3\cup\sum\nolimits_4.\))给出两个序列,\(\mathcal s,\mathcal t\),定义推广子序列核(Generalized Subsequence kernel),\(K_n(s,t,\lambda)\)来计算长度为n的赋权特征稀疏子序列\(\mathcal u\),具体过程如下:
\[u \prec s[ii] and \ u \prec t[jj](对于某些长度为n的序列中标号为ii,jj子序列)\] \[u的权重为\lambda^{l(ii)+l(jj)}(0 < \lambda < 1,并且l(ii)是子序列的长度,\\ 它是ii中最大序号和最小序号的差,解析这些子序列,低的是它的权重)\]
在这里,\(\prec\)表示属于某关系,例如,如果\(ii=(i_1,i_2,\dots,i_{\left\|u\right\|})\)并且\(u\prec s[ii]\),于是有\(u[1]\in s[i_1],u[2]\in s[i_2],\dots,u[\left\|u\right\|]\in s[i_{\left\|u\right\|}]\)。
假设\(ii=(1,2,4)\)有\((NNP,'s,NN)\prec s[ii]\),考虑上图中的s和t,可以看到有某些长度为3的稀疏子序列:
(NNP, ‘s, NN);(NOUN, ‘s, NN);(NNP, POS, NN);(NOUN, ‘s, NOUN)
通过下面的递归式子可以高效的计算s和t生成的子序列核
$K_0^\prime(s,t)=1,for all s,t$
$K_i^{\prime\prime}(sx,ty)=\lambda K_i^{\prime\prime}(sx,t)+\lambda^2K_{i-1}^\prime(s,t)\cdot c(x,y)$
\[K_i^\prime(sx,t)=\lambda K_i^\prime(s,t)+K_i^{\prime\prime}(sx,t)\] \[K_n(sx,t)=K_n(s,t)+\sum_j\lambda^2K_{n-1}^\prime(s,t[1:j-1])\cdot c(x,t[j])\]
Relation Kernel(rK)
定义为4个子核的和,每个子核有有一个基于子序列生成的特殊的模式类型。
Fore-Between subkernel(fbK)
计算前缘(Fore-Between)模式之间的相同点(\(s_fs_b^\prime\)和\(t_ft_b^\prime\)的共享子序列)(\(\underline{president}\ PER \ \underline{of}\ ORG\))
Between subkernel(bK)
计算模式之间的相同点(\(s_b^\prime\)和\(t_b^\prime\)之间的共享子序列)(\(PER\ \underline{joined}\ ORG\))
Between After subkernel(baK)
计算between-after模式之间的相似度(\(s_b^\prime s_a\)和\(t_b^\prime t_a\))(\(PER\ \underline{chairman \ of}\ ORG\ \underline{announced}\))
Modifier subkernel(mK)
如果两个实体间没有其他词语,并且第一个词语是修饰另一个的,则可以使用修饰模式。这个子核计算了修饰模式间的相似度(\(x_1x_2\)和\(y_1y_2\))(ex:Serbian general,第一个Serbian修饰general)
rK的总式子
\[rK(s,t)=fbK(s,t)+bK(s,t)+baK(s,t)+mK(s,t)\]用SVM基于rK分类,有两种场景
- 只训练一个多分类的SVM去判断每个关系类型属于一个类并且NONE类表示不属于任何类型
- 训练一个二分类SVM去决定是否存在关系(将所有的关系认为属于同一个类),另外再训练一个多分类的SVM去决定pos实例中的具体类别(比前一种方法好)
语法树核 Syntactic Tree Kernel
将一个句子中的成分定义为一个语法树,内容包括名词短语(noun phrases,NP),动词短语(verb phrases,VP),介词短语(prepositional phrases,PP),标点符号(POS tags,ex:NN,VB,IN,etc)作为非终结符号并且实际单词作为叶子。

语法树例子
一般语法由上下文无关文法(CFG)产生。
卷积分析树核 Convolution Parse Tree Kernel(\(K_T\))
KT用来计算两个语法树之间的相似性。KT计算两个语法分析树之间共享的子树。在这里,子树被定义为符合以下两种情况的树中的子图
i)应当不止包含一个节点
ii)结果必须被包含在整个节点中
每个可能的子树视为投影空间中的一个维度。树T在变换空间(transformed space)中定义为\(h(T)=[h_1(T),h_2(T),\dots h_n(T)]\),其中\(h_i(T)\)表示T中第i个子树并且n表示所有子树的数量。对任意两个子树T1和T2,核的值就是它们在变换空间的简单投影。\(K_T(T_1,T_2)=h(T_1)\cdot (T_2)\)
高效计算
因为所有的可能的子树数量是很多的,所以不存在可以直接计算图像向量的方法。因此,核必须被在不涉及对所有可能子树的遍历下进行。如果第i个子树根在节点n,则令\(I_i(n)=1\),否则\(I_i(n)=0\)。令N1和N2分别是树T
和T2的节点集合。
\[h_i(T_1)=\sum_{n_1\in N_1}I_i(n_1),h_i(T_2)=\sum_{n_2\in N_2}I_i(n_2)\\ h(T_1)\cdot h(T_2)=\sum_ih_i(T_1)h_i(T_2)=\sum_{n_1\in N_1}\sum_{n_2\in N_2}\sum_iI_i(n_1)I_i(n2)=\sum_{n_1\in N_1}\sum_{n_2\in N_2}C(n_1,n_2)\]其中,C(n1,n2)计算每个根在n1和n2之间的子树的数量,可以通过以下的迭代步骤在多项式时间完成
1.如果\(n_1 \& n_2\)处的乘积不同,\(C(n_1,n_2)=0\)
2.如果\(n_1\&n_2\)处的乘积相同,并且\(n_1\),\(n_2\)都是预终端(pre-terminals),\(C(n_1,n_2)=1\)
3.如果\(n_1\&n_2\)处的乘积相同,并且\(n_1\),\(n_2\)都不是预终端,\(C(n_1,n_2)=\prod_{j=1}^{nc(n_1)}(1+C(ch(n_1,j),ch(n_2,j)))\),nc(n)代表n的节点数量,ch(n,j)代表n的第j个子节点。
关系实体表示
一个句子包含\(N_e\)个实体,就有\(\left(N_e\ 2\right)\)种关系实例。因此,在完整的语法树中找出一个特别的关系是很重要的。
1.最小完全树(Minimum Complete Tree,MCT):是有两个实体通过最低共同祖先生成的完全子树。
2.路径封闭树(Paht-enclosed Tree,PT):最小的一个包含两个实体的子树,也可以表示为连接两个实体间的最短路径对应的路径封闭树。
3.上下文有关路径树(Context-sensitive Path Tree,CPT):是PT的拓展版本。额外包含了第一个实体的左边的第一个词语和第二个实体的右边第一个单词。
4.扁平路径封闭树(Flattened Path-enclosed Tree,FPT):是PT的改良版本,忽视只有一条进出的弧的non-POS non-terminal的节点。
5.扁平上下文有关路径树(Flattened Context-sensitive Path Tree,FCPT),CPT的改良版本,忽视只有一条进出的弧的non-POS non-terminal的节点。
依存树核
句子中的词语间的语法关系被他们的语法依存树所编码。词语在句子中是树中的节点,并且依存关系是边。

依存树示例
关系表示
对句子中的每个实体对,考虑包含这个实体对的最小依存子树。依存树中的每个节点由附加信息加强,包括POS tag, generalized POS tag, chunk tag, entity type, entity level (name, nominal, pronoun), WordNet hypernyms and relation argument .
正式地,一个关系实例是由这样一个增强依存树T定义的,T有节点\(\{t_0,\dots,t_n\}\),其中对于每个节点\(t_i\)有特征\(\phi(t_i)=\{v_1\dots v_d\}\)。定义\(t_i[c]\)表示\(t_i\)的所有的孩子,\(t_i\cdot p\)表示\(t_i\)的父节点,\(t_i[jj]\)表示\(t_i\)的一组特殊的子节点,其中\(jj=j_1,j_2,\dots,j_{l(jj)}(j_1<j_2<\dots<j_l(jj))\),\(l(jj)\)是序列的长度,其对应的稀疏表示\(d(jj)=j_{1(jj)}-j_1+1\)是一个指数递增序列。

在上图中,\(t_0[c]=t0[{0,1}]={t_1,t_2},t_1\cdot p=t_0\)
为比较两个节点\(t_i,t_j\),定义了两个方程。
-
Matching function(\(m(t_i,t_j)\))
如果在\(t_i\)和\(t_j\)之间有重要的相同特征就返回1,否则返回0
-
Similarity function(\(s(t_i,t_j)\))
返回一个正实数值来表示\(t_i\)和\(t_j\)之间的评分,
\[s(t_i,t_j)=\sum_{v_q\in\phi(t_i)}\sum_{v_r\in\phi(t_j)}C(v_q,v_r)\]其中,\(C(v_q,v_r)\)是两个特征的值\(v_q\),\(v_r\)之间的比较函数,最简单一种形式是,如果\(v_q=v_r\)返回1,否则返回0。
依存树核\(K(T_1,T_2)\)衡量了两棵依存树T1和T2(根分别为t0,t1),定义如下
\[如果m(t_{10},t_{20})=0,K(T_1,T_2)=0\\否则K(T_1,T_2)=s(t_{10},t_{20})+K_c(t_{10}[c],t_{20}[c])\\其中,K_c(t_{10}[c],t_{20}[c])是一个核函数,具体为\\\sum_{ii,jj;l(ii)=l(jj)}\lambda^{d(ii)+d(jj)}\left(\sum_{s=1}^{l(ii)}K(t[i_s],t[j_s)])\right)\prod_{s=1}^{l(ii)}m(t_i[i_s],t_j[j_s])\]直观的可以知道,任何时候一对匹配的节点找到后,所有它们可能的匹配的子节点也找到了。两个子序列被认为匹配的前提是他们所有的节点都是成对匹配的,将它们所有的相似度评分相加得到一个总的子节点的相似度,\(0<\lambda<1\)作为一个衰退因子来惩罚稀疏的序列。
一个特殊的临近核(contiguous kernel)也可以来限制子序列\(ii\),例如\(d(ii)=l(ii)\)。除了稀疏树核(K0),临近树核(K1),还有词袋(bag-of-words)核(K2,将树视为一个向量,不考虑树的结构),也可以组合使用\(K_3=K_0+K_1\),\(K_4=K_1+K_2\)。
依存图路径核 Dependency Graph Path Kernel
找出最短依存路径中相似的地方。考虑<leaders, Venice>这个例子,其中最短路径为:\(leaders\rightarrow were\leftarrow in \leftarrow Venice\)完全的词汇化的路线可能导致数据稀疏。因此,将词语分类为POS tags,generalized POS tags,Named Entity types。因此,现在是这样的形式:
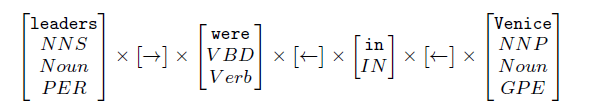
每个可能的路径被考虑为一个特征,因此,可能就有各种情况的特征:
\[leaders\rightarrow were \leftarrow in \leftarrow Venice\\NNS\rightarrow were \leftarrow in \leftarrow Venice\\NNS \rightarrow VBD \leftarrow in \leftarrow GPE\\ etc.\]一共有\(4\times1\times3\times1\times2\times1\times4=96\)种可能的特征。短路径依存路径核(Shorted Dependency Path Kernel)计算两种关系种共同的路径特征,假设有两个关系R1,R2,\(R_1=x_{11}x_{12}\dots x_{1m},R_2=x_{21}x_{22}\dots x_{2n}\)分别为其最短路径,那么核的计算方式如下:
\[K(R_1,R_2)=\prod_{i=1}^nc(x_{1i},x_{2i}),m=n\\K(R1,R2)=0,m\neq n\]考虑另一个例子:

比较两个例子, 计算它们的核为\(2\times1\times2\times1\times1\times1\times2=8\),它们共同的特征值就是8。这种依存路径核通过一个强加的限制(两条路径的长度应该相等)来解释,而卷积依存路径通过寻找两个依存序列的子序列让这种做法更灵活。
混合核(Composite Kernels)
使用语义树核(KT)和实体核(KE),有
Linear Combination
\[K_{LC}=\alpha\cdot NK_E+(1-\alpha)\cdot NK_T\]Polynomial Expansion
\[K_{PE}=\alpha\cdot(1+NK_E)^2+(1-\alpha)\cdot NK_T\]\(NK_E(NK_T)\)是核的归一化后的表示。
\[NK_E(R1,R2)=\frac{K_E(R1,R2)}{\sqrt{K_E(R_1,R_1)K_E(R_2,R_2)}}\]评估

有监督方法比较
将实体抽取和关系抽取组合
先前提到的所有RE技术都是由实体的边界和类型的知识,如果预先没有实体的知识,为了运用这些RE技术,首先要运用一些实体抽取技术。一旦实体和它们所属的类型被确定了,就可以运用RE技术了。但是,这里存在一种错误的传播的可能,一旦实体和它们的类型判断错了,后面的关系抽取很大概率也是错误的,为了避免这种情况的发生,应当将实体抽取与关系抽取综合考虑。
基于整数线性规划的方法 Integer Linear Programming based Approach
给定一个句子,在推断的过程中,会产生一个符合特定域(domain-specific)和特定任务(task-specific)限制的全局决策。一个简单的关于限制的例子:关系PER-SOC两端的实体都应该是PER。考虑这个句子 John married Paris。实体抽取找出了两个实体John和Paris,对于第一个实体,假设其预测的概率:\(Pr(PER)=0.99;Pr(ORG)=0.01\),对第二个实体,假设其预测概率为:\(Pr(GPE)=0.75;Pr(PER)=0.25\)。同时,RE判断这两个实体之间的关系为PER-SOC,我们可以判断出John(PER)和Paris(GPE)之间是PER-SOC关系,但是这违背了上述的限制。因此,满足所有特定限制的全局决策应该把两个实体都识别为PER并且认为它们是PER-SOC关系,通过基于整数线性规划的方法可以解决限定域的问题.
基于整数的线性规划最小化任务成本函数(assignment cost function)和限制成本函数(constraint cost function)的和。任务成本函数是寻找局部分类器在有最大的可能性的同时有最小的成本;限制成本函数是施加对于打破实体与关系的成本。
基于图模型的方法 Graphical Models based Approach
一种通过局部独立分类器(local independent classifiers)学习实体和关系分类的框架。实体与关系之间的依赖关系通过一种二分(二分图)的,无回路有向的贝叶斯信念网络(bayesian belief network)。
| 实体用二分图中某一层中的节点表示,关系用另一层的节点表示。每个关系节点\(R_{ij}\)有两个来自其相关的实体\(E_i,E_j\)的入边,给定一个表示句子的特征向量X,局部实体和关系分类器被用来分别计算$$P_r(E_i | X),P_r(R_{ij} | X)\(,编码通过条件概率\)P_r(R_{ij} | E_i,E_j)$$来限制,这个概率可以通过人为的通过已标注的语料库来确定。最大化贝叶斯网络这些节点的联合概率去得到实体和关系最有可能的标签分布,例如: |
卡片金字塔解析 Card-Pyramid Parsing
这种方法将实体与关系中的共同依赖用一种类似于打牌时的金字塔型结构的图结构。这种类树(tree-like)的图在最高层有一个根,内部节点在中间层,叶子节点在最底层。句子中的每个实体对应一个叶子节点,并且如果有n片叶子,那么这个树就有n层。每层\(l\)包含的节点比前一层\(l-1\)少一个。在\(l\)层的第i个节点是\(l-1\)层第i个和第i+1个节点的父节点,每个更高层的节点(除了最底层),对应一个它低一层最左边和最右边的节点之间可能的关系。

卡片金字塔示例
这种结构的目的是联合标记卡片金字塔中的节点。一种上下文无关语法的自底向上的解析算法可以分析卡片金字塔。这种算法用到的语法被称为卡片金字塔语法(Card-pyramid grammar),它包含如下映射类型:
-
实体映射 Entity Productions
\[EntityType\rightarrow Entity,e.g.PER\rightarrow leaders\]一个局部实体分类器被训练了用来计算每个在式子右边的实体被式子左边的类型映射的概率。
-
关系映射 Relation Productions
\[RelationType\rightarrow EntityType1\ EntityType2,e.g.PHYS\rightarrow PER\ GPE\]一个局部关系分类器被训练了来预测左边关系映射到右边实体对的概率。
给定句子中的实体,卡片金子塔语法和局部实体与关系分类器,卡片金字塔算法尝试去找出最有可能根据实体与关系类型的节点标签。
结构化预测 Structured Prediction
在大部分的联合实体抽取与关系抽取中,假设实体边界(boundaries)总是知道的。有一种同时提取实体和关系的增量联合框架,包含了实体提及的边界问题。早期的方法独立的对实体与关系的局部分类器建模。即使后面做出了最佳的全局决策,实体抽取和关系抽取在训练过程中也不允许交互,因此提出一种将这类问题作为一个结构化预测的问题。这种算法尝试预测对于给定句子(\(x \in X\))的输出结构(\(y\in Y\)),其中这种结构被认为是一种将实体作为节点,关系为带有标签的边的图模型。使用下述式子来预测最有可能的结构\(y^\prime\),其中\(f(x,y)\)是对整个结构的特征向量:
\[y^\prime=arg\max_{y\in Y(x)}f(x,y)\cdot \vec w\]每种候选分布被定义为特征向量\(f(x,y)\)和特征权重\(\vec w\)的内积。但对于一个句子可能的结构的数量可能非常巨大并且没有一个多项式时间的算法可以找到最优的结构,因此,应用束搜索(beam-search)对输入句子逐步的扩展局部的配置去寻找分数最高的接结构。为了解码,使用半马尔可夫链(每种状态对应输入句子中的一段)而不是将单独的词语当作状态。
Features
在对实体抽取和关系抽取使用不同的局部特征的同时,这种算法框架一个主要优点是任意的这两种任务的特征可以很好的被发现。某些实体抽取使用的全局特征被用来尝试找出实体间长距离依赖,如:
-
共指一致性 Co-reference consistency
同一个句子中的两个切片(segment)之间的共指连接由某些简单的启发式规则决定的。一个全局特征被编码来检查两个共指的切片是否共享同样的实体类型。
-
邻居一致性 Neighbour coherence
两个相邻的切片的实体类型作为一个全局特征连接起来。
-
部分-整体一致性 Part-of-whole consistency
如果一个实体是某个实体中的一部分(由依赖连接\(prep\_of\)连接),它们应该被认为是同一种实体类型.
in some of Italy’s leaders
some 和 leaders应该都属于同一实体类型PER。
某些RE的全局特征如下:
-
三角约束 Triangle constraint
多个实体不太可能与相同的关系类型完全连接。一个negative特征被用来惩罚任何包含这种形式的结构。
-
相互依赖的兼容性 Inter-dependent compatibility
如果两个实体通过一个依赖连接而连接起来,它们应该与其它的实体之间的关系有同样的兼容性。
Jhon and Mary visited Germany
Jhon 和 Mary之间是\(conj\_and\)连接,因此它们应该与Germany有同样的关系。
另一种联合考虑的方法使用表结构(table structure)。这张表代表了句子中的实体和关系结构,对于有n个词语的句子,这张表是一个\(n\times n\)的下三角矩阵,其中第i个对角线单元代表了第i个词语的实体类型。任何(i,j)单元代表第i个词语开头的实体与第j个词语开头的实体之间关系(如果它们之间存在关系)。利用这张表,联合抽取问题被映射为一个表填充(table-filling)问题,其中标签被分配到表中的单元中去。
半监督方法 Semi-supervised Approaches
为RE产生标签数据是很费时费力的事情,设计半监督方法的主要动机有两个,
- 减少人工成本去标注数据
- 利用产出容易的大量的无标注数据
自举方法 Bootstrapping Approaches
大体上,自举算法需要大量未标记的语料库并且一部分令人感兴趣的种子(seed)关系实例,比如,想要学习抽取关系\(CaptialOf\)的模型/模式,种子实例可以是\(<Beijign,China>,<New Delhi, India>,<London,England>\)给定了这些种子,一个自举算法期望可以抽取一样的关系,例如\(<Paris,France>\)。
双型迭代模型关系扩展 Dual Iterative Pattern Relaiton Expansion(DIPRE)
隐藏在这个算法背后的符合直觉的知识是模式关系的对偶性(Pattern Relaiton Duality)指:
- 给定一组有效的模式,一组有效的元组(遵循特定类型的一对实体)可以被找到
- 给定一组有效的元组,一组有效的模式可以被学习
考虑到这个对偶性,DIPRE的算法如下:

DIPRE算法
输入:一组种子元组S(包含已知的特定的关系的元组)
输出:经过多轮迭代的S
1.找到网络中所有S中出现的元组
2.从这些找到的元组中学习模式
3.用学习到的模式去网络上搜索新的元组并添加进S
4.返回1,不停迭代知道没有新的元组加入S
将实体E1,E2间的关系定义R为一个五元组\((order,urlprefix,prefix,middle,suffix)\)。其中order是一个布尔值,其他值都是字符串。如果\(order=true\),一对实体(E1,E2)匹配定义的模式。一个符合这样的模式的例子如下:
\[(true,"en.wikipedia.org/wiki/",City\ of,is\ capital \ of,state)\]匹配句子:CIty of Mumbai is capital of Maharashtra state.
SnowBall
一种基于DIPRE的改进模型,主要在两个地方改进:
- 模式的表示和生成:使用词的向量来代表DIPRE中的字符串
- 模式和元组评估方法:丢弃了不够准确的模式,
主动学习 Active Learning
主动学习技术现在在机器学习领域广泛使用了来减少创造标签数据的注解工作。主动学习背后的关键思想是,允许请求获得某些未标注数据的真实标签。人们提出了各种不同的标准来选择这些实例,其共同目标是用很少的实例快速学习基本假设。与监督学习的方法相比,主动学习的重要的一个优势是只需要少量的标签数据。
主动学习系统LGGo-Tesing
LGGo-Testing建立在主动学习方法Co-testing(协同训练)之上,为了应用Co-testing,有两种看关系实力的视角:
- 一个基于获取联系着的实体特征和包含的句子中的其他特征的局部视角
- 一个基于使用大型语料库的,联系两个实体的短句的分布相似性的全局视角
假设对于一个类型为PHYS的实体,它紧接着的短语是\(travelled\ to\),其他相似的表述有\(arrived in,visited.etc\)。如果在一个大型语料库中,两个短语在相似的上下文环境中,那么它们有相近的分布。一个最大熵分类器使用局部视角的特征来训练。在使用分类器时,全局视角下使用了分布相似性的最近邻分类器来寻找最近邻。
标签传播方法 Label Propagation Methond
标签传播方法是一种基于半监督方法的图,其中数据中标注的和为未标注的实例都被表示为图中的节点,并且图中的边用来反应节点的相似性。在这种方法中,任意节点的标签的信息被迭代的通过加权边传播到临近的节点,当传播过程是收敛的,那么最后原来的未标注标签节点的标签可以被推断出来。
使用前文提到的基于特征的方法,关系实例\(R_i\)和\(R_j\)之间的边有以下权重:
\[W_{ij}=\exp\left (\frac{s_{ij}}{\sigma^2}\right)\]其中,\(s_{ij}\)是与\(R_i\)和\(R_j\)之间特征向量的相似性,\(\sigma^2\)用来规范权重(这里标签间的平均权重)
其它方法
多任务迁移学习(multi-task transfer learning)
用来解决一个弱监督RE问题,具体为关系类型中只有少量种子实例,但是有大量其他标注了的其他类型的实例。某些特定的关系类型可以用通用的结构。比如ACE关系中,EMP-ORG(employees of TCS)和GPE-AFF(residents of India),都是通过介词结构联系,因此可以用迁移学习来做(共享权重向量)。
无监督方法 Unsupervised Relation Extraction
无监督方法不需要任何已标注数据
聚类方法 Clustering based approaches
最早的无监督RE只需要一个NER标记(tagger)去区分已命名了的实体,这样系统就只要聚焦于已命名的实体。
这种方法通过以下的几步实现:
- 语料库中的命名实体被标记出来
- 成对发生的命名实体被创建并且它们的上下文被记录下来
- 计算step2中标出的实体对之间的上下文的相关性
- 使用step3中计算出的相似性值来将实体对聚类
- 每个被聚的类代表一个关系,一个标签自动的根据类中代表的关系来标注这个类
命名实体对和上下文 Named Entity(NE)pairs and context
如果两个实体之间之多有N个词,那么这两个实体就可以称作同时发生的。构建这些同时出现的实体对。观察所有特定的命名实体对,并且记录所有的这样的实体对间的中间词语作为上下文,并且第一个命名实体的左边和第二个命名实体的右边的词语不是上下文。这是这种方法的第一个限制,不是所有的关系都只通过中间词语来表述,比如\(CEO\ of\ ORG,\ PER\ announced\ the\ financial\ results\),并且命名实体的顺序也是很重要的,同一实体对但顺序不同的也应该分别记录其上下文。
上下文相似度计算 Context similarity computation
对每个命名实体对,使用所有出现在其上下文中的词语构建一个词向量。每个词语的权重为\(TF\times IDF\),值得一提的是,对于TF的计算有个有趣的方法,如果一个词语w在上下文(NE1,NE2)中出现L次,在(NE2,NE1)中出现M次,那么w的TF值为L-M。两个实体对之间上下文相似度为计算它们所对应词向量的余弦相似度,值从-1到1之间,1表示两个实体对完全匹配,-1表示有共同上下文但是两个实体对中的实体位置相反的。
聚类和贴标 Clustering and Labelling
利用相似度值,使用全连接的层次聚类方法来聚类命名实体对。聚类结果的标签由类中所有的命名实体对上下文中的高频词自动生成。
对于基础的聚类方法,有一种利用无监督特征选择方法去移除相似度计算中的无意义噪声词语的改进方法。
概念对 Concept pairs
另一种利用维基百科数据的无监督RE方法中,没有使用命名实体对,而是使用了维基百科结构(Wikipedia)的概念对(Concept pairs)。对于一篇维基百科文章,它的题目是主要概念(principal concept)并且与其他连接当前文章的次级概念(secondary concept)配对。具体聚类方法分为两步:
- 使用连接两个概念的深度语言模式的相似度来对概念对聚类,这些语言模式由句子中的依存树中产生
- 对尚未聚类的概念对,使用聚类中的形心来聚类。
发现推导规则 DIscovery of Inference Rules
另一种方向的无监督方法是基于从生成的依赖路径中推导关系类型。DIRT算法基于分布相似度假设,不应用这个假设去寻找相近的词语,而是去发现联系同一组词的相近的路线。
半监督语义解析 Unsupervised Semantic Parsing
一种类似的方法,迭代的对依存树中传递同样意思的语法片段进行聚类。
另一种对关系实例聚类的方法使用生成概率模型(和LDA类似,基于标题模型(topic model))。这些模型表示代表实体类型间构建的关系类型和连接的依赖路径的不同的特征。
其它方法
无监督关系抽取系统 Unsupervised RE System(URES)
一种非聚类的无监督RE方法是URES,URES唯一的输入是对于关系类型的定义。一个关系类型被定义为很多指定这种关系类型和实体的参数的关键词,例如对于关系Acquisition,关键词可以是acquired,acquisition。URES是KnowItAll system的直接继承,KnowItAll system从网页中抽取事实,KnowItAll 主要是实体抽取,而URES主要是关系抽取。在URES的基础之上,加上一个基于NER的简单规则,可以更好的改善结果。
无监督释义获取 Unsupervised paraphrase acquisition
另一种方法是基于使用无监督释义获得RE,对于表示同样意义的文本表述,把它称作释义(paraphrases)。这个方法从一个文本表述开始(相应的语法结构类似依存结构)表示目标关系并且使用无监督方式找到它的释义。例如,开始时的表述\(X\ interact\ with\ Y\),释义获取算法会产生新的表述\(X\ bind\ to\ Y,X\ activate\ Y,X\ stimulate\ Y,interaction\ between\ X\ and\ Y,etc\)
开放信息抽取 Open Information Extraction
传统的RE关注准确、提前特化的关系,需要大量的人为参与设计抽取规则或者创建标注数据。因此,针对不同域的问题,这种系统很难行之有效。为了克服这些限制,开放信息抽取(Open IE)范式被以TextRunner系统提出来了。Open IE自动地发现语料库中的关系而不需要人为的参与。因此,当转移到不同域的问题时没有额外的工作要做。
TextRunner系统包含以下三个核心模组:
-
自我监督学习器 Self-supervised Learner
使用一些启发式的规则,它会自动的标注一组抽取的实体元组为postive或者negative。在这里,pos类表示关联的元组代表某些有效的关系。经过自动标注后,每个元组被映射为一个特征向量,并且训练一个朴素贝叶斯(Naive Bayes)分类器。
-
单次通过抽取器 Single Pass Extractor
对整个语料库应用单次通过,得到所有句子的POS和NP信息。对每个实例,每对NPs(E1和E2)作为候选元组并且通过测试它们之间的文本找到相应的关系R。对每个它们之间的词,启发式的决定是否在R中包含它们。每个候选元组被输入进朴素贝叶斯分类器,并且只有分类为postive的例子会被抽取并保存。
-
基于冗余的评估器 Redundancy-based Assessor
在对整个语料库进行抽取后,TextRunner自动的合并某些实体和关系都一样的元组。对每个元组,包含它的独特的句子的个数也被记录下来并且评估器使用这些数量去衡量每个元组正确的概率
使用基于状态随机场(Conditional Random Field)的自我监督序列分类器O-CRF来代替朴素贝叶斯分类器去改善TextRunner的结果。
另一种对TextRunner的改进为使用维基百科开放抽取系统(Wikipedia-based Open Extractor,WOE),通过维基百科的信息框生成更加准确的自我监督学习器中的训练数据。
自举的方法,像Snowball减少了初始训练的例子,但是这些方法并没有应用于Open IE系统,于是有一种改进的自举算法StatSnowball可以被应用与Open IE。
ReVerb
一种克服了TextRunner中下列限制的Open IE系统:
-
没有逻辑的抽取 Incoherent Extractions
从句子中抽取出来的关系可能是没有意义的。这样的抽取是一个字一个字的决定一个词是否包括在一个关系短语的结果。
-
没有有效信息的抽取 Uninformative Extractions
这些抽取忽视了重要的信息,通常是由对关系短语处理不当造成的,这些短语由轻动词结构(Light Verb Constructions,LVCs)表示。LVCs是一个多词语的表述方式,包括一个动词和一个名词,并且名词含有语义内容。比如,is the author of。在句子John made a promise to Alice中,TextRunner提取了一个没有有效信息的元组(John,made,a promise),正确的抽取应该是(John,made a promise to,Alice)。
-
过分具体的抽取 Overly-specific Extractions
TextRunner可能会抽取过度明确而无用的关系,比如(The Obama administration,is offering only modest greenhouses gas reduction targets at, the conference)
为了克服以上的限制,ReVerb算法使用下面两种约束来做抽取。
-
语义约束 Syntactic Constraint
通过约束关系短语去匹配下表的POS tag模式:

这个约束限制了关系短语只能是下面几种中的一种:动词(e.g. invented);紧接着介词的动词(e.g. born at);紧接着名词、形容词或副词并以介词结尾的(e.g. has atomic weight of);多个相邻的匹配项合成一个单独的关系短语(e.g. wants to extend)。这样可以避免抽取出没有逻辑的短语,因为这样无需在孤立的词语级别的判别是否应该在某个关系短语中包含这个词,这样是判别一组词语是否符合POS模式。这样同样也可以避免无效信息的抽取,因为名词也允许是关系短语中的一部分并且符合LVCs模式的关系也可以被找到。
-
词汇约束 Lexical Constraint
为了避免过分具体的关系短语,使用词汇约束时只考虑那些采用至少k个不同的参数对的关系短语。例如短语took control over是有效的,因为其在多种参数时都生效,像(Germany,took control over,Austria)和(Modi,took control over,administration)
ReVerb与TextRunner在区分关系短语时的方法是不同的,ReVeb从整体的角度区分关系短语,而不是从单个词语的角度。
在ReVerb的基础上再加上一个模块ArgLearner来区分短语中的参数可以提高ReVerb中区分出的关系短语中的参数的准确率。
这些开放信息抽取系统中有一个主要的限制是具有同样语义的关系可能会被多个关系短语表示并且这些关系短语要通过后续处理来巩固。
远程监督 Distant Supervision
远程监督是一种不要求标注数据的替代的范式,它利用自动获取关系标签的大的语义数据库。这些标签可能是有噪声的,但是大量的训练数据可以抵消这些噪声。与之相近的还有个思路,创作“弱”标签的数据。
远程监督综合了两种模式(监督的和无监督的)的优势。在监督模式上,它使用概率性的分类器结合了成千的特征;在无监督模式上,它从任意域中的大量语料库中抽取了很多数量的关系。
方法提出者使用了Freebase作为语义数据库,Freebase中存有表示不同关系的实体对。
启发式标注 Labelling heuristic
如果两个实体出现在一个关系中,任何包含它们的句子都有可能表示这个关系。举个例子,一个实体对<M. Night Shyamalan,The Sixth Sence>对应关系/film/director/film,因此下面这两个句子都有可能给这种关系提供正面的支持:
- M. Night Shyamalan gained international recognition when he wrote and directed 1999’s The Sixth Sence.
- The Sixth Sence is a 1999 American supernatural thriller drama film written and directed by M. Night Shyamalan.
负面实例 Negative Instances
上面提出的启发式方法只能找到正面实例。为了训练分类器,正面实例和负面实例都是需要的。在Freebase中未出现的实体对被任意的选出作为负面实例。但是因为Freebase的不完善性,某些实体对可能会被错误的打上负面的标签。
一个使用高斯正则化的多分类的逻辑斯蒂分类器(multi-class Logistic Classifier with Gaussian regularization)使用自动获取的标签来训练。不同的词汇,语义和命名实体类型特征都被用来训练。
多实例多标签方法 The Multi-instance Multi-label learning based approach(MIML-RE)
传统远程监督方法的一个主要缺点是没有能对互相重叠的关系建模。比如,某些相同的实体对,可能有不同的有效的实体关系,元组(Steve Jobs,Apple)可以是FoundedBy关系也可以是CEO关系。
MIML-RE为实体的多个的实例建模了潜在的标签,并且它还为单个实体对的标签之间的依赖关系建模。MIML-RE使用一种新的图形模型来表示一个实体对的多个实例以及多个标签。一个提及(mention)层面的分类器使用提及的上下文来对实体对中的每个提及的关系进行分类。还有另外一组分类器,在实体对级别上操作每个远程关系标签。这些都是二分类的分类器,表示实体对之间是否有特定的关系。
这些分类器可以认识到两种关系,比如Born In和Spouse Of不能由同一个实体对生成。如果提及层面的分类器在低一层对这两种关系的标签都分配到了同样的元组,那么实体对层面的分类器可以取消其中一个标签。这些分类器也可以学习什么时候两种标签趋向于同时出现,就像CapitalOf和ContainedIn。为了学习图模型的中的不同参数,需要采用EM算法。
近期,远程监督RE成为了非常活跃的领域并且有一些新的方法来改进特定的问题。因为语义词典库的不完整性,有些negative的实例实际上是正确的。为了克服这个问题,一种算法是只从positive例子和未标注数据中学习;一种算法是对伪negative例子采用伪反馈信息检索技术。
MIML-RE的数据可能的表述的一个问题是这是一个非凸公式。一种有识别能力的聚类可以使其变为凸公式。
本体论平滑 Ontological Smoothing
如果知识数据库不是明确非凸的,那么远程监督是不能应用的。当只要有某些关系的种子例子时,本体论平滑方法就可以用来解决上述问题。OS方法产生一个关系和知识库的映射。这样的映射关系被用来生成额外的训练样本,之后可以用远程监督学习RE。
联合使用远程监督和直接监督可以显著的提高RE的表现。
使用主动学习远程监督
使用主动学习去提供一个对MIML-RE有偏向性的监督。使用一个新的选择关系实例的标准,偏向于选择不确定的(在分类器中容易引起高度分歧)和有代表性的(与大量未标注实例类似)的实例。
近期RE的进展 Recent Advances in Relation Extraction
通用模式 Universal Schemas
将现存的结构化数据库(像Free Base,Yago等)联合起来并且将Open IE中可能的关系类型以表面(surface)形式形成通用模式。
US在通用关系类型(universal relation)中学习非对称含义。这种含义可以帮助从结构化数据库中的一组关系中推断出符合实体对的关系。如果一个城市和一个国家之间的关系是CapitalOf,那么也可以推断出关系LocatedIn也符合这个城市和国家。但是这种非对称关系反过来不一定能够成立。
n元关系抽取 n-ary Relation Extraction
关系间的元组超过2个,比如EMP-ORG-DESG,例子为句子Jhon Smith is the CEO of ABC Corp(Jhon Smith,CEO,ABC Corp.)。
早期对n元关系抽取实验的是做法是从二元关系中形成一个图,其中实体是节点,实体间之间的关系是边。从图中找出最大集群,每个集群对应着某种n元关系。
另一种角度看n元关系RE问题是语义角色标签(Semantic Roles Labelling,SRL)。SRL从给定的句子中自动的区分谓语和它的元素。
交叉句子关系抽取 Cross-sentence Relation Extraction
目前主要探讨的技术都是句子中的RE(intra-sentential RE),有些时候句子间也存在RE,如下图

句间RE
应用结构化特征(如分析树路径)和句内RE的技术来做句子间的RE。一般来说,可以通过共指关系来解决句子间RE的问题。
卷积深度神经网络 Convolutional Deep Neural Network
在不经过复杂NLP分析的前提下,使用卷积DNN去抽取词语级别与句子级别的特征。自动学习出来的特征可能比人为设计的特征更有效。另一种类似的做法是利用RNN。
交叉语言注释投影 Cross-lingual Annotation Projection
实体和标注数据只能从某些语料丰富的语言(英文,中文,阿拉伯语等)中获得。因此需要一种关系投影方案将预料丰富的语言投影到语料不丰富的语言。
域适应 Domain Adaptation
监督学习系统的基本假设是训练数据和测试数据是符合同样的分布的。但是当数据分布不匹配时,RE表现就会打折扣,这种情况往往发生在区分域外的数据时。通过将从单词聚类和潜在语义分析(LSA)中获得的语义相似信息嵌入到语法树内核中,可以提高基于核的系统的域外性能。
结论和展望
尽管目前最先进的RE技术已经在近十年来发展的很好,但仍有一下几个方向具有很大的潜力。
- 现在已经有一些技巧综合考虑实体和关系抽取了,但是当数据集不够好时,算法表现往往较差,因此可以设计出更精致的模型。
- 现在对n元关系抽取做的工作还很少,因此需要更多有效的方法。
- 大部分的RE研究都是在英语之上完成,剩下的很大部分是中文和阿拉伯语。分析现有的有效的和语言无关的方法是很有潜力的。对于语料贫瘠的语言(缺少使用的NLP预处理工具,如POS标签,parsers等),还有很多系统的工作去做。
- 大部分RE中的NLP处理步骤受到词语(lexical)和句法(syntax)的限制,只有少数技术用到浅层的语义处理。分析语义和语篇层次等更深层次的自然语言处理是否有助于提高再加工能力,将是很有意义的。

